多模态数据湖系统的可能形态
本文尝试从 Google 发表的部分论文看一个可能的多模态系统的可能。主要围绕 BigQuery,对训练推理的涉及较少,是一个支持多模态(结构化、半结构化和非结构化数据)的 Data Infra。这些也可以应用在以 OpenSource 组件为基础的系统上。
这里的多模态数据湖系统包括数据的摄入,存储,管理(&优化),以及查询,并且包括全链路的权限管理等,支持跨云跨域的操作。同时给用户一定的灵活度,可以在不同的场景下选取最优的方案。
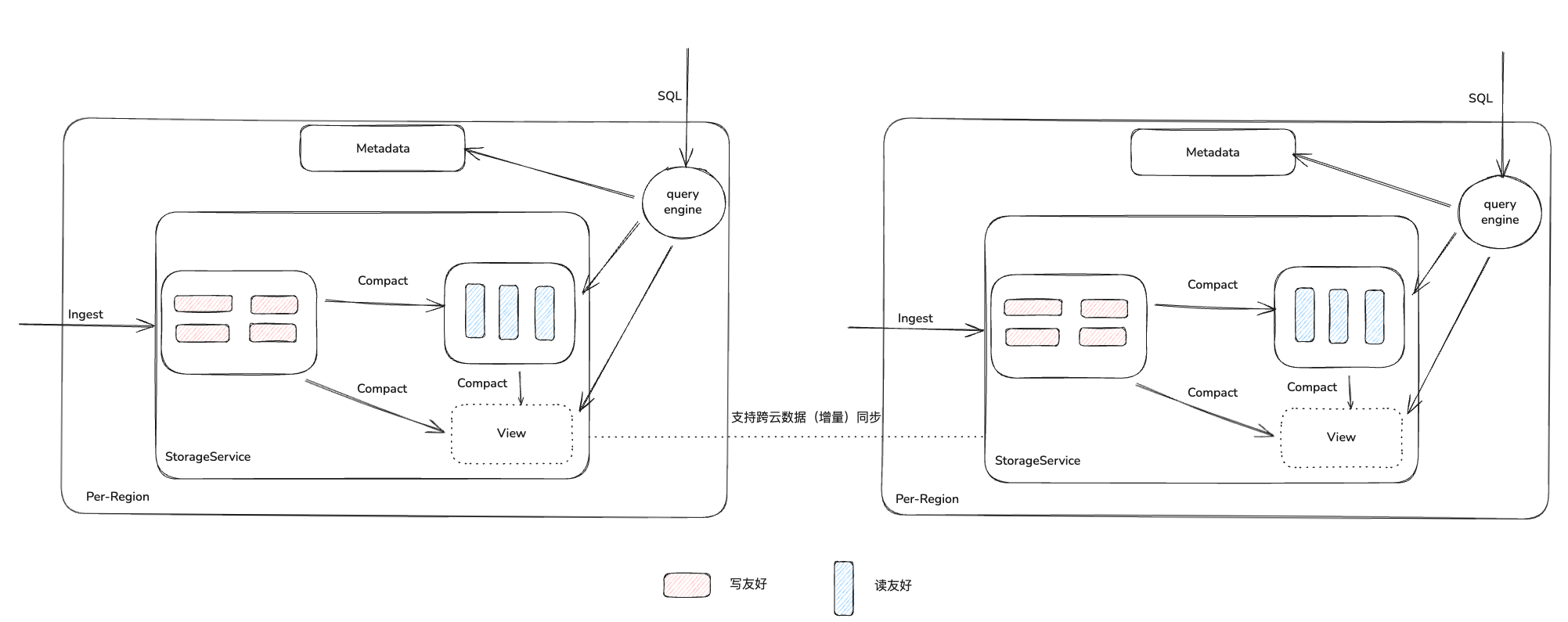
一个简化后的系统图如上所示,下文会分模块来介绍
Vortex
在 列存文件格式对比 一文中我们有描述 column file format 相关的内容,在 file format 之上会有存储引擎,Vortex[1] 是 BigQuery 中一个同时支持 streaming 和 batch 的存储系统,支持 sub-seconde 的 latency。
Vortext 拥有如下的特点
- 支持 ACID 语义
- Unified API for both streaming and batch
- Scalable:可扩展性,支持分布式的
- Performance:极佳性能,sub-second 的 tail write latency
在 BigQuery 中所有的数据都与一个 DataSet — 传统 db 的 schema — 进行绑定,table/view/mv/index/stored procedures/machine learning models 等都是一个 dataset。
Stream 是一个可追加数据的逻辑实体(A Vortex Stream is an entity to which rows can be appended to the current end)。Stream 中的 row 由 <id, offset> 进行定位,同一个 Stream 支持并发读取不同的 row。表是一系列未排序的 Stream 的集合。
一个 Stream 包括多个 Streamlet,Streamlet 是 Stream 中一组连续的 row 的集合,并且 Streamlet 会在多个集群进行冗余存储。每个 Stream 最多只有一个可写的 Streamlet,且一定是最后一个 Streamlet。Streamlet 是逻辑概念,支持横向扩展:比如客户想写入大量数据,可以同时创建多个 Streamlet,每个 Streamlet 分配到不同的 StreamServer 中,可以打算压力。
一个 Streamlet 包括多个 Fragment,Fragment 是 Streamlet 中连续 row 的块,一般是一个 log file 中连续的一部分,log file 存在分布式文件系统 Colossus 中。其中 Streamlet 和 Fragment 是 Vortext 内部概念,用户无感知。Fragement 和 log file 是保存在分布式文件系统上的, 如果 StreamServer 挂了,只需在新 StreamServer 上重建对应关系即可。
Log file 是具体的物理文件,这些文件在 Vortex 中有两种:WOS(写友好)和 ROS(读友好),分别用于不同的场景(BigQuery 的 ROS 是 Capacitor,BigLake 的则是 Parquet)。
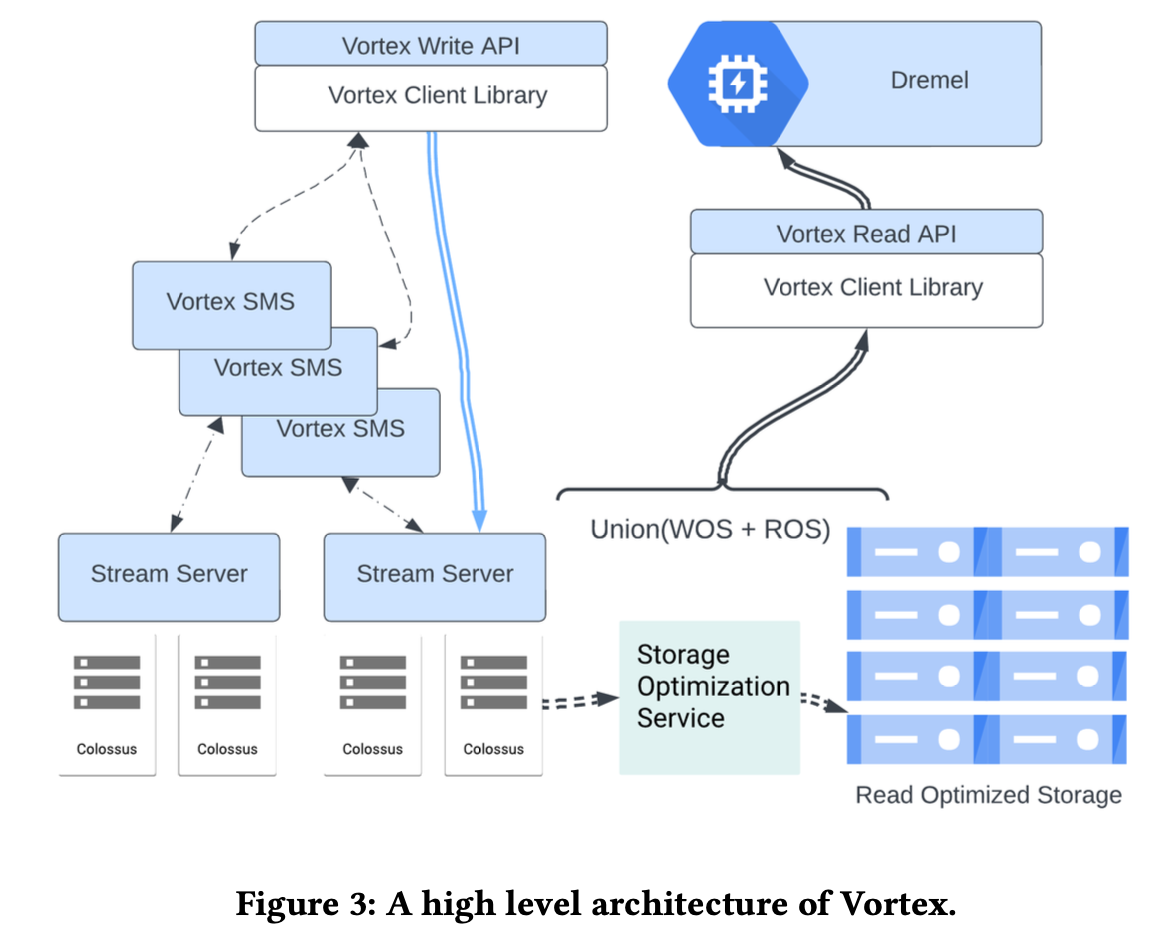
架构如上
Steram Metadata Server(SMS) 是 Vortext 的管理面板,负责将 Streamlet 赋值给指定的 Stream Server,Stream Server 负责维护 Steramlet 的 Fragement。StreamServer 会在自己本地维护一个有关 Streamlet 和 Fragement 的 metadata,这些信息会周期性的写 transaction log 并做 checkpoint。metadata 包括 Fragement 和 Streamlet 的关系,commit size,每个 fragement 中 minimum 和 maximum record timestamp,schema version,partition 以及 cluster column 信息等。
写入流程:Client 和 SMS 交互创建一个 Stream,SMS 会生成一个 StreamId 然后 assign 到一个 StreamServer,Client 直接往 StreamServer 写数据,StreamServer 会周期性的通过心跳同步当前的数据。
Storage Server 会从 SMS 请求一批 Fragments 将其转为 ROS 格式,同时把原来的 Fragement 标记为 DELETED,SMS 会在一段时间后通知 StreamServer 删除过期的 Fragements。延迟删除是为了避免正在进行的查询出现 FileNotFound。
StreamServer 和 SMS 会有心跳,包括 Stream Server 上所有 Streamlet 的新元数据,包括「新文件、已有文件的新大小、列信息,以及 server 的 cpu/memory/append throughput 等」,Stream Server 需要成功写入两个 Colossus 集群后才返回给客户,为了避免一些潜在的 bug,Stream Server 会周期性的将全量信息同步给 SMS。
每个 fragment header 包括相同 Streamlet 中已有 fragement 的 file map,file map 包括 committed size,record range 等。在恢复时仅需要读取最后一个 fragement 的 header 即可。
ServerServer 会 Buffer 2MB 数据后再写入到文件中,以方便可以减少小文件,另外可以更好的利用压缩。写入会携带 TrueTime(时间戳),表示当前所有 row 的写入时间。后续 stream server 会进行压缩,加密,然后写入到 log file 中。Log file 的结构大致如下(其中 [...] 是一个 fragement)
| [header | data | bloom filter | offset of bloom filter] | [...] | [...] |
元数据使用 BigMetadata 进行管理,对于部分尚未同步到 BigMetadata 的新数据,会导致查询不及时,该情况使用持续的 metadata entries compaction 机制来保证和 Fragement 一致,会维护一个 Fragement 的 watermark ,文件合并流程由 Storage Optimizer 合并 Fragement 的时候触发。
Vortext 支持 Fragement/Streamlet 的一批 row 同时标记为 DELETED(Vortex allows a range of rows in a Fragment or Streamlet to be marked as deleted),为了控制 delete mark 的大小,部分未实际删除的行也会被标记为 DELETED,这些被称为 reinsert rows,reinsert row 会和 delete mark 一起写入到新的 Fragement 并提交。更新使用 UPDATE = [DELETE + INSERT] 替代。
为了防止 Optimizer 和 DML 冲突,在做 DML 的过程中,会停止 Optimize,DML 可能耗时较长,则将 WOS 文件1->1 的转换成 ROS, DML 还是可以对转换后的 ROS 数据做标记(和 WOS 一样)。
BigMetadata
BigMetadata 主要的想法
- 使用系统表形式保存 metadata,可以对 metadata 使用 query engine 进行操作,扩展性更好
- 提出了 falsifiable expression,可以改写 condition,更大规模的过滤数据
随着数据越来越多,可以通过减少 metadata 来增加整个系统的扩展性,但会影响查询性能,BigMetadata 则不需要在扩展性和性能之间做取舍,可以同时拥有扩展性和高性能。
构建一套分布式的 metadata 管理系统用于存储 column/block 的 metadata(支持任意大小的表),把 metadata 作为系统表,这样 metadata 和 data 都可以用一套 query engine 进行处理
- Consistent(统一)
- Built for both batch and streaming API(流批统一)
- (Almost) Infinitely scallable :近似无限的扩展性,支持单表 PB 级别(metadata,data)
- 性能好
metadata 分为两种:logical 和 physical
- logical metadata 是用户直接可见的,比如 schema,partition/clustering spec,column/row ACL 等,数据量一般不大
- physical meadata 是表存储相关的,比如 table 和 data 位置信息等
每一列在 BigMetadata 中会有 totalRows/totalNulls/totalBytes/min/max/dictionary/bloom_filter 等信息。
Metadata 有 changelog,使用 LSM 的方式来周期性的进行合并,如果某些 row 的信息还没有被更新,则会记录在 ingestion server 的内存中。
falsifiable expression 主要用于查询的时候进行过滤从而加速,比如 x > c 的条件,如果我们知道 max(x) <= c 的话,那么整个都可以被过滤掉。
一些可转化例子如下
x > c, x < c=>max(x) <=c, min(x) >= cx between c1 and c2=>min(x) > c2 OR max(x) < c1x in (c1, ..., cN)=>(min(x) > c1 OR max(x) < c1) AND ... AND (min(x) >cN OR max(x) < cN)
下面的一些条件可以先进行等价的转换,再使用 falsifiable 进行过滤,等价转换如下所示
NOT(p or q), NOT(p and q)=>(NOT p) AND (NOT q)x + c1 > c2=>x > (c2 - c1)DATE_SUB(x, c1)< c2=>x < DATE_ADD(c2, c1)x LIKE 'c%' / REGEXP(x, 'c.*')/STARTS_WITH(x, 'c')=>x > 'c' AND x < 'd'
Napa
Napa 一文提出了经常被提到的不可能三角:Data fresshness,Resource cost 以及 Queyr performance,三者最多只能满足两个。Napa 的主要设计包括
- Robust QueryPerformance:Consistent query performance is critical to data analytics users,查询性能需要稳定
- Flexibility:用户可以通过简单配置适应不同场景:查询性能/成本/新鲜度。
- High-trhoghput Data Ingestion:支持高吞吐的写入,包括 Napa function,storage,materialized view maintenance 以及 index 等。
Napa 的架构分为三部分
- ingestion framework 负责数据写入,主要考虑写入性能
- storage framework 负责数据的维护,包括:1)增量的更新新写入数据对应的元数据,从而可以被查询到;2)对数据进行周期性合并提升查询性能
- query serving 应对客户查询。必要时在 query 中对 delta 进行合并(不管是 table 还是 view)
把系统拆分为三部分可以更好的满足不同需求,用户可以在不可能三角中进行选择。
架构如下所示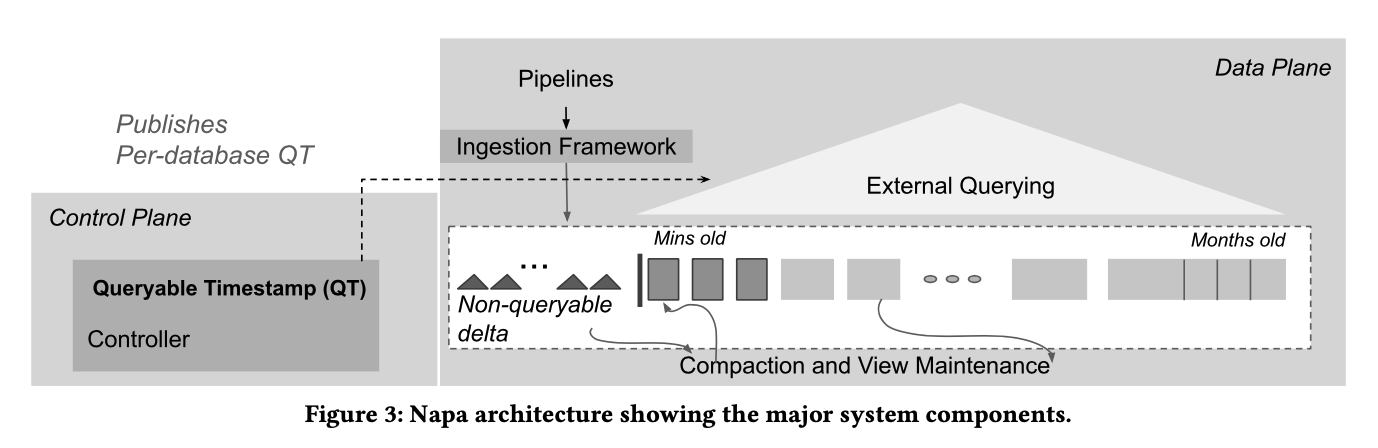
用户可以在不同的维度进行选择,如下所示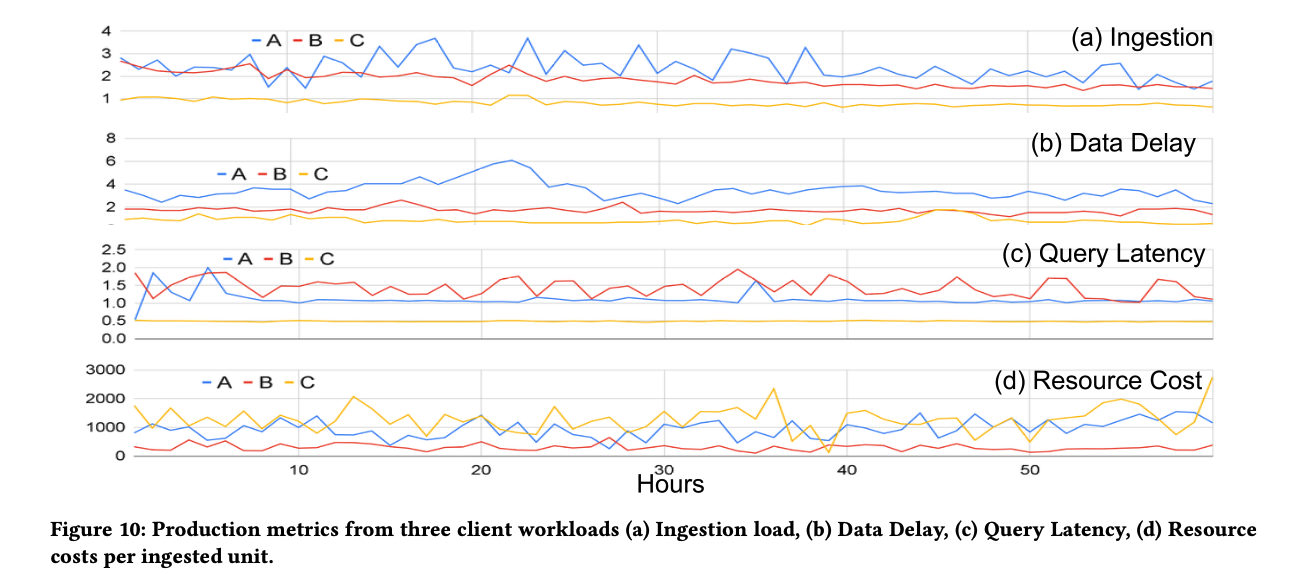
ingestion framework 只需考虑更快的写入数据,storage framework 考虑如何更快的合并 delta,query serving 则需要考虑 cache ,prefetch 以及 merge delta 等提供更好的查询性能。query serving 的目标是低延迟的反馈给客户, 低延迟一部分可以通过预计算的 MV 来处理,另外可以通过并行化 query 进行处理。延时的方差则通过 merge delta 的 fan-in 来进行控制。
Napa 通过控制 compaction(table/view) 的调度来控制 delta 的数量,compaction 需要保证数据在可控的成本(cost)范围内尽可能的新鲜(freshness)。
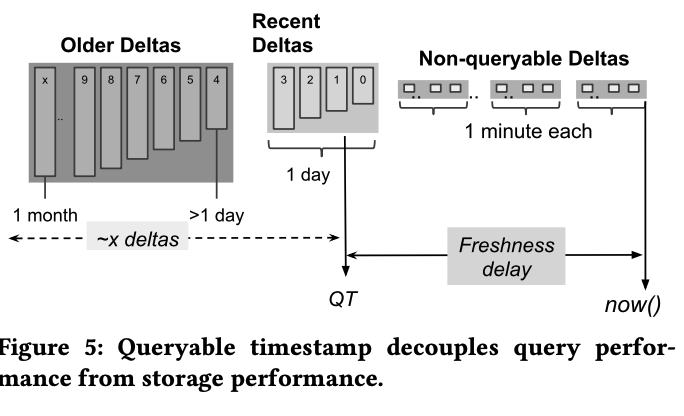
Napa 中的 table 是所有 delta 的集合,最新写入的 delta 没法被查询到,通常会在最新的 time window 中,watermark 之前的数据才能被查询到,每个 delta 根据 key 进行排序,使用 range 进行 partition,并且有一个局部的 btree index。
Storage subsystem 主要对存储内容进行优化,1)对 input 进行排序;2)对同一行的 update 进行聚合,因为每个 delta 都是排好序的,所以合并就是 merge sort,会尽可能保证 detla 足够大,这样 delta 的 tree height 就不会太高,减少查询时所需的 key 比较次数更少。
通过如下方法保证查询性能
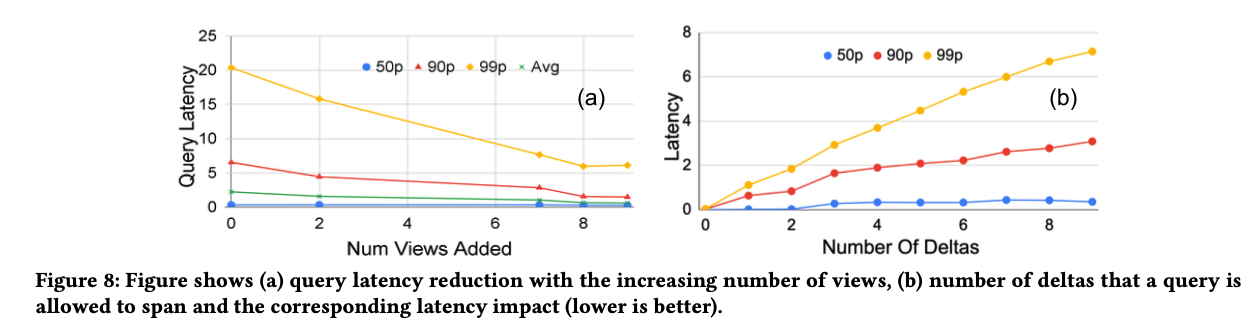
- 减少核心路径中的数据:Napa 会在 query 中尽一切可能使用 View 而不是 base table,因为 view 会比 base table 拥有更少的数据(且可能已经聚合过);会使用 delta 最底层(leaf node)的 btree 来进行 partition(后面续渐进式有讲),将原 query 拆分成多个小 query 并行化。不同数目的 view/delta 和查询性能的关系如下图所示
- 减少(查询时的) IO:首先使用 QT(watermark) 来确定需要处理的 metadata 版本以及相关数据,然后通过 metadata 的 cache 机制保证 metadata 的访问不需要 IO;另外会使用 online/offline 的 prefetching 来减少核心链路上的 IO 访问次数:一是 dry run;二是对于查询多的表,在 QT 推进之后就对新数据进行 prefetch
- 对小 IO 进行合并:Napa 使用 query 拆分并行查询,这可能会导致 tail letency 更严重,因此使用 QT(watermark) 来限制可查询增量的数量,另外还通过:1)跨 delta 的延迟合并以及基于磁盘大小的布局尽可能的合并小的 IO
- lazy merging across deltas: 假设有 thousands(N) 个 subquery 以及 tens(M) deltas 的时候, IO 的并发是
N*M,但是每个 subquery 只读取每个 delta 很少的一部分数据,另外大部分 query 需要对最后数据进行聚合,Napa 的 plan 会避免跨 DeltaServer 的 merge,这样可以让每个 DeltaServer 处理一个 delta,这样可以将N*M降到 ~ N - size-based disk layout: Napa 使用自定义的 columnar storage 支持不同的磁盘布局格式,可以根据不同的 delta 大小来选择布局。比如 delta 小的时候选择 PAX 布局,可以一次性读取所有列的数据,对于大的 delta 则是每一列单独存储,这样 scan 更友好(但 point query 不友好)
- lazy merging across deltas: 假设有 thousands(N) 个 subquery 以及 tens(M) deltas 的时候, IO 的并发是
相比完全避免 tail latency,Napa 选择容忍 tail latency,因为完全避免的成本太高而且不现实。生产中选择 hedging 的方式(类似预测执行)来处理 tail latency,如果 rpc 在固定时间没有返回,发起第二次 rpc,然后选择更早回来的那一个。对于 streaming 的读取,使用处理进度来衡量时延,进度比预期慢时会触发第二个请求,需要特别注意 filter 的情况,filter 的进度可能会发生跳跃 — 进度从很小一下调到很大,Napa 使用已经处理的 bytes 数据量来解决这种情况。
Napa 将 ingest 和 view maintaince 拆开,可以很好的应对不同场景的 infra 问题,比如 ingest 速度变化很大,或者 view maintain 出问题,都不太影响 query performance,如下图所示,(a) 中的 ingest rate 有较大变化,但是性能基本没啥波动,(b) 中 X 和 Y 之间 view 的维护出问题,除了 freshness (c) 受影响,query performance 不受影响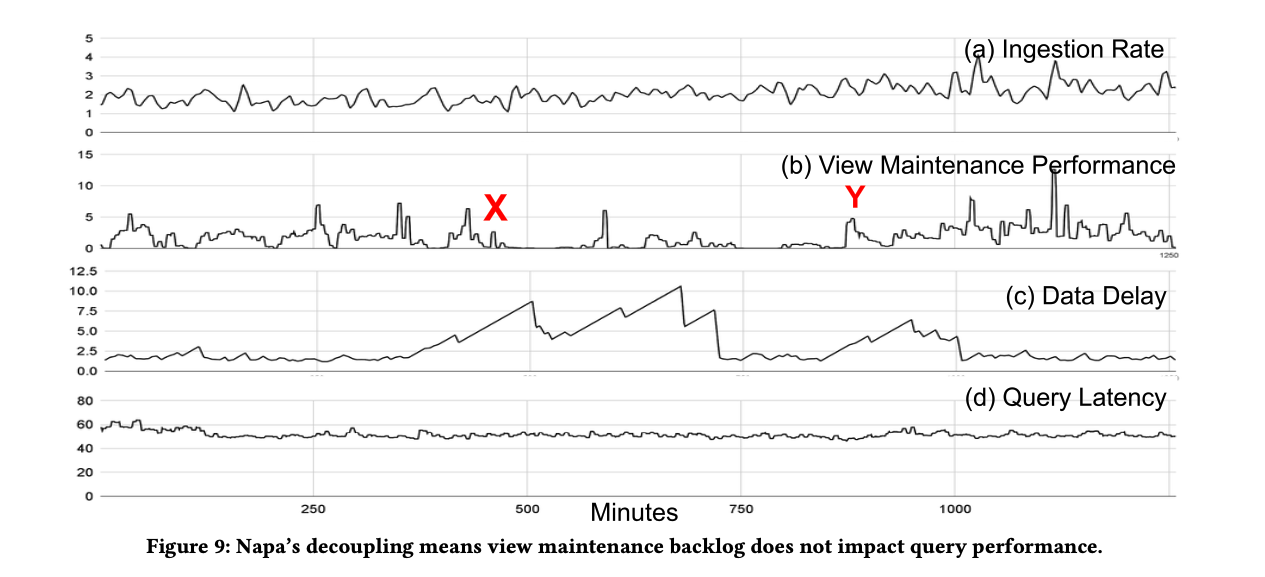
除了上面的情况外,Napa 使用 progressive query-specific partitioing 来保证验证的 SLO[4],在这个方案中,采用 足够好 的分区方式(可以保证更好的 robust),既能保持每个分区的查询时间,同时又保持不同分区间的数据均衡。该方案使用基于统计信息的 b-tree 变种实现辅助查询以及分区选择的双重目标。
从生产中可以观察到如下:query specific partitioing、evenness、progressvieness 在实践中很重要。具体的分区需要根据 query 进行调整,从而满足延迟和成本的要求,分区的预期是在可控的误差范围之内(也就是足够好);需要考虑分区之间的均衡(多 key 查询的时候,可能造成部分 partition 的数据比其他 partition 数据多很多);「足够好」就行,因为找合适的 plan 需要花时间,如果因为寻找最优的 plan,导致最终未满足 SLO 的要求则会得不偿失,因此当分区满足系统要求后就可以立即停止进一步优化。具体表现是:plan 的质量和时间成正比;一旦达到期望的误差范围内,就停止继续探索更优的 plan。
比较 high-level 层面的 index 如下所示
Napa 团队在线上实验发现太精细的统计信息可能会导致生成 plan 的过程耗时太多,从而影响整体的执行时间,Napa 中使用 BTree 来进行优化,在 LSM Tree 的最底层是 B-Tree,BTree 会包括相关的统计信息,生成 plan 时从 BTree 的 root node 开始,如果当前层统计信息不够准确或者发现有数据倾斜等,则继续使用 BTree 下一层数据尝试生成 Plan,Napa 中的算法是利用 BTree 生成 even and query-specific 的 partition,在每一层会判断当前生成的 partition 是否「足够好」(满足对应的误差),如果不满足,就继续使用更下一层的信息。
BTree 的 node 增加了层级统计信息,会在每个 subtree 中保存 key 的数目,这些数据逐层往上进行聚合。进行分区的输入是 queried keys,使用 B-Tree 的信息来生成近似的 histogram,从 root 开始进行 partition,最终停在 partition 「足够好」的 level。
为什么不直接用 LSM 呢?
- 查询的时候,可能会覆盖 LSM 中很多 delta,甚至需要处理所有的 delta
- 第二个,部分 delta 可能数据量更多(数据倾斜),导致 partition 不均匀
- 第三个,查询可能会涉及多个 delta,每个 detla 的贡献(涉及的 row)不一样,因此 delta 的切分粒度会不一样。
为什么要用渐进式 per-query 的 partition 方式?
- 不同 query 的 partition 有其独特性,处理数据从 MB(使用 1000 worker 读取 GB数据) 级别到 GB 级别(使用 1000 woker 读取 TB 数据)都有
- 对于部分常见的 filter (Date = d3) 来说,需要和其他 key 一起进行切分(比如
- 同一个表,不同的 查询条件/延迟预期/以及资源消耗等 对 partition 的粒度要求也不同
- 写入时候分区的算法无法对处理上述的场景
Progressive partitioning 的流程
首先,对于每个 delta 都维护一个 size-enhanced B-tree,每个节点中增加数据大小的统计信息,BTree 中的信息指向文件中的数据块(比如 PAX 布局中的一个 block),这样不仅可以帮助前缀高效查询数据,还提供分区的统计信息。所有的查询(是否带 partition)都会经过这个 BTree,这个 BTree 用于帮助寻找「足够好」的分区。
BTree 的 node e = <start, end, size, level, block> 这里 start 表示起点的 key,end 是结束的 key,size 是总 key 大小,level 是层数,level 0 表示 leaf,block 指向 child index block
具体的算法如下
对于某个 query Q 来说,会将 D 个 deltas 分成 P 个不重合的 parititon,且误差在 $\theta$ 之内。通过 BTre 的信息来估计整体数据大小,进行分区操作,按需访问 BTree 的下一层节点。
比如下图的 query 命中两个 delta,两个 delta 都有 drill down(访问非 root 层),第一个 delta 停在了最底层,第二个 delta 在第二层就停止了(满足了「足够好」的要求)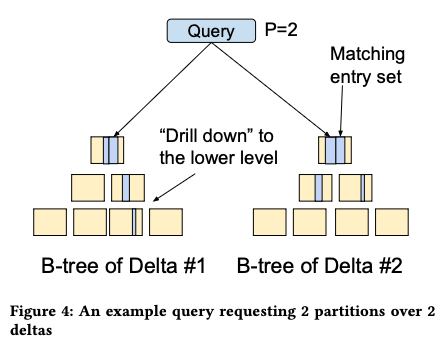
这两个 delta 的 BTree 的信息如下所示(中间括号内的数字是 key 的数目)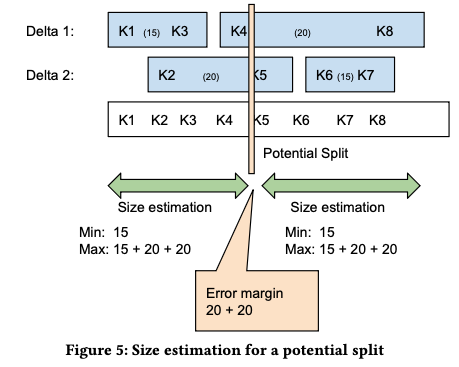
整个查询分成两个 partition 并行处理的话,考虑第一层的时候,Delta1 的 [K1, K3) 有 15 个,[K4, K8) 有 20 个数据;Delta2 的 [k2, K5) 有 20 个数据,[K6, K7) 有 15 个, 这些数据总和加起来是 15 + 20 + 20 + 15 = 70 个。首先会选择在 K4 和 K5 之间做分割,这样可以分成 [K4, K8) 和 [K2, K5) 做一些分割,然后对于第一个 partition,大小可能是 15 (也就是 [K2, K5) 的数据全部倾斜在右侧,[K4, K8) 也倾斜),同样最大的可能是 15+20+20 =55,那么估算这个大小均值是 (15 + 55) / 2 = 35 ,然后 size margin = 55-15 = 40,同样第二个 partition 类似,得到估算大小是 35,size margin 是 40,如果 (40/35, 40/35) — 两个 partition 的误差 — 能满足 $\theta$,那么就按照这样进行切分,如果不行,就继续往 B-Tree 的下一层再进行切分。
E 表示某个 BTree 节点的整体范围(也就是整个 delta),然后 e 表示其中一个 entry(一个 sub 节点),因为 E 是一个上限(粗略估算),如果我们需要更精细的数据,在 BTree 上进行 drilldown 的时候(在实现中,由于这个会设计到 IO,因此会打包执行,然后利用 IO 的并行性),算法如下所示1
2Algorithm DrillDown(E, e, Q)
return E \ {e} union { c | c in GetBlockEntries(e.block) AND [c.start, c.end) join Q != empty}
知道了有哪些集合之后就需要找切分点(split point),首先需要找到一些可选的切分点,
每个 $E_i$ 中与 Q 有交集的点都记录下来并排好序,集合 K = {k1, k2, …, k_m} (这个是按照 e 的 start 或者 end 排好序的), 计算 cumulative size C = {c1, c2, …, c_m}, 根据目标 partition 大小,从 K 中挑出 split point 从而让实际的 partition size 和目标的 partition size 最小(the actual partition size and the target partition size is minimized). (k_i, k_{i+1}] 之间的点叫做 split point candidate at i)。
其中 cumulative size ($c_{i}$) 是 $(-\infty, k_{i}]$ 范围内所有符合条件的数据的估算量,在这里会维护一个 $c_{i}.min$ 和 $c_{i}.max$,其中 $c_{i}.min$ 是 [e.start, e.end] 中 key 前缀 p 满足 $p \in (k_i, k_{i+1}]$ 的最小值,然后 $c_{i}.max$ 则是这个范围内可能的最大值,比如在上图(Figure 5)中,可选的切分点如果在 K4 这里的话,那么最小的则是 [K1, K3], 最大的则是 [K1, K3,], [K2, K5] 以及 [K4, K8].
相邻两点(i 和 j, i < j)之间的 partition 使用如下指标进行评估
- i 和 j 的 partition size $size(i, j) = (|c_j.min - c_i.max| + |c_j.max - c_i.min|)$
- partition 的边距(size margin) $margin(i) = c_i.max - c_i.min$
其中 $size(i, j)$ 是 partition 的平均最大和最小值,$margin(i)$ 和 $margin(j)$ 则提供了 $size(i, j)$ 两端的评估精度,如果 $margin(i) / size(i, j) > \theta$ 则我们认为 i 侧的边距过大(we consider the margin at i is too large for the partition between i and j)
对于 cumulative size $C = {c_1,…,c_m}$ 以及目标 partition size P,会找到一些候选点 $S = {s_1, …, s_{P-1}}$ ($s_i \in [1, m)$), 然后使用贪心算法进行
- 首先计算每个点的 cumulative size $T = {t_1, …, T_{P-1}}$ 其中 $t_k = TOTALSIZE(\varepsilon) * k/P$,比如 $TOTALSIZE(\varepsilon) = 1000, P = 10$ 的情况下 $T = {100, 200, …, 900}$,其中 $TOTALSIZE(\varepsilon) = \sum_{e \in \varepsilon} e.size$ 这些 e 之前已经命中的那些 block 的 size, 然后从一个离 $t_k$ 最近的点,$s_k = argmin_i=1,…,{m-1}max(|t_k-c_i.min|, |t_k-c_i.max|)$,由于 target size 是严格递增的,因此这个在 $O(min(Plog_m, P+m))$ 时间内完成,其中 P 是 partition 数目,m 是 distinct key 的数目。
然后对 partition 切分进行评估 $U = \{s_i | s_i \in S, (s_i = s_{i+1}) \cup (margin(s_i)/size(s_{i-1}, s_i) > \theta) \cup (margin(s_i)/size(s_i, s_{i+1}) > \theta)\}$,如果 U 不为空就需要进行 drill down,如果 U 为空,则表示满足要求
整体算法如下所示
BigLake
BigLake 主要讲了 BigQuery 的跨云实现。BigQuery 的用户有几个核心需求:1)需要有核心数据管理能力(security, governance, common runtime metadata, perforamce, ACID, etc); 2) 支持开源的各种 format 以及分析生态,并且支持类似 AI/ML 等 unstructured data。
BigQuery 尝试解决如下几个问题
- BigLake tables, 将 open format 作为 first class citizens 支持,提供 finegrained govenrnace enforcement 以及 performance acceleration
- BigLake Object table 支持 unstructured data
- Omni,支持在 non-GCP 上跑 BigQuery
BigQuery 支持 Delegated Access Model 来解决直接用 Object storage 的一些不便之处
- 绕过了当前的系统不太好做精细化的权限管控(credential forwarding implies that the user has direct access to raw data files, which would allow users to bypass fine-grained access controls such as data masking or row-level security)
- BigLake 也有一些非用户直接发起的操作(比如 metadata refresh,reclustering)等需要有访问(BigLake tables need to access storage outside of the context of a query to perform maintenance operations, for example refreshing the metadata cache or backgroupd data reclustering)
提供 Fine-Grained Security(包括 row/column level 的信息)
- 提供统一的 row/column 的 fine-grained 权限控制(且独立于存储与引擎).BigLake tables provides consistent and unified fine-grained(row and column level) access controls independent of storage(data lake or data warehouse) or analytics engine(BigQuery or opensource query engines like Spark).
- 可以对 object store/私有存储中的都使用同一套 column-security/data masking/row-level filter 实现。For BigQuery users, the delegated access model enables BigQuery to enforce column-security, data masking and row-level filtering using the same implementation for data in object stores or in its native storage
- 现在开源的实现中会依赖具体的引擎,这个和引擎绑定,无法跨引擎通用。The current status quo in open-source analytics places the responsibility of enforcing the fine-grained access controls with the query engines. This leads to two downsides: 1) security policies such as data masking and row-level filtering are tied to a SQL dialect, requring duplication of governance policies across multiple query engines. 2) the model of entrusting the query engine to enforce filtering to not work well on engines like Apache Spark that are designed to run arbitrary procedural code directly within the query engine worker processes.
BigLake table 提供一个更强的安全模型,ReadAPI 支持 finegrained access control,这样数据在返回 query engine 之前就进行了数据权限控制,这样也可以对任何的查询引擎支持 zero trust 的操作。
对于开源的 table format(Iceberg 等),metadata 通常比较有限(Hive 需要 list,Iceberg 需要读取 manifest 然后进行解析等),BigLake 支持 metadata 的 cache(这里用到 BigMetadata),这些 metadata 会在文件写入到 object store 后自动更新。
跨云的安全控制如下所示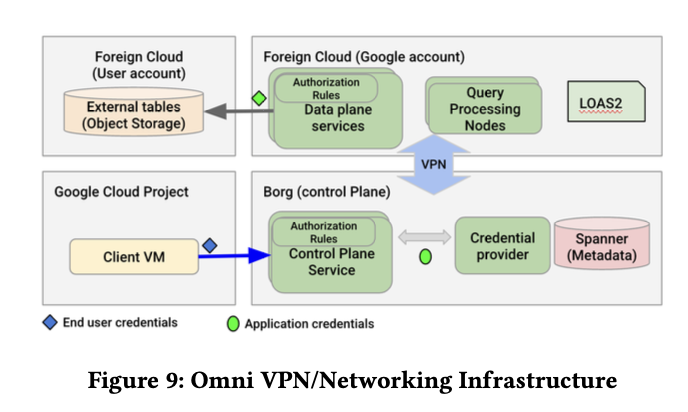
现在非结构化数据越来越多,BigQuery 提供了 Object Table,可以用 SQL 来分析 Object table,然后可以在 SQL 中嵌入小的非结构化处理,也可以使用外置更专业的组件处理。Object Table 会包括 URL/object size/ MIME type/time 等属性,SELECT * 有点类似 ls 或者 dir 的输出结果,另外支持 fine grained security 以及扩展性。
在跨云(跨域)的分析中,之前有使用 ETL 在不同地域进行数据同步的,有使用 federation 的,但都存在一些问题
- 比如 ELT 的方式
- data staleness 数据延迟
- egress and data storage cost(带宽和存储成本的放大)
- complexity (太复杂)
- compliance(e.g., data wipeout) concers(合规问题)
- Federation 的方式
- 最后需要在多个地域之间聚合,带宽会比较大
在常态环境中不支持跨云查询的原因
- 数据传输成本高(need for a bandwidth-intensive and expensive cross-region data transfer in the general case)
- 远程获取 metadata/data 难(the difficulty of accessing table metadata and data in other locations.
Bigquery 的 Omini 与上述方案不一致,会在多云环境中部署 query engine,查询时对 sub query 进行 pushdown,最后进行聚合。
Bigquery 收到用户 SQL 的时候会进行解析,如果所有 source 在同一个 region 就正常处理; 否则,就从其他地域拉取 metadata,将 query 拆分成 per region 的 subquery,并附带一定的 filter pushdown,然后提交新的 query 到往远程 region,将其结果注册成一个本地临时表,本地最后使用临时表进行继续处理。
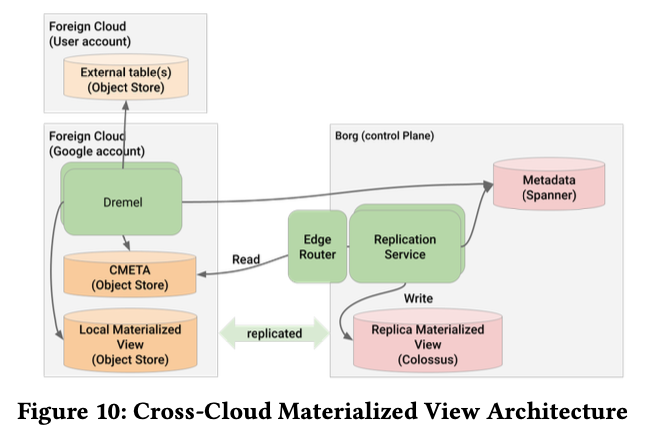
Omini 支持跨云的增量物化视图更新: 现在本地构建一个增量 MV 并落盘,通过 file 在多云之间进行传输,特殊情况(比如 upsert/delete 导致 MV 更新特别多的情况下)会通过删除本地的 MV 并重建,来减少数据传输。
Procella
Procella 是 YouTube 的一个 unify 引擎,Youtube 的场景包括:reporting and dashboarding, embedded statistics in pages, time-series monitoring, 以及 ad-hoc analysis。一般企业会每种场景搭建一套 infra,但这样会导致数据冗余且维护成本高,因此 YouTube 创建了 Procella。
上述场景有不同的要求
- Reporting and dashboarding: 创作者,或者内部管理者需要访问实时的 dashboard 了解 video/channel 的情况,这要求引擎支持每秒执行数万个预设的 query,并且保证低延迟,这些 query 可能包扩 filter/aggration,set opeartion 以及 join 等。这里的挑战是:数据量太大(每天每张表可能有百亿级别的新数据),结果需要根据最新的数据做实时计算
- 嵌入式统计:比如 YouTube 的视频点赞或观看次数等,这些查询简单,但是基数非常大,而且值不停的在变化,因此系统必须支持每秒数百万的实时更新和数百万次的低延迟查询
- 监控:监控和 dashboard 有很多共同之处,相对简单的预设查询和对新数据的需求,这些一般是内部使用,所以查询量不大,但是需要 自动 downsampling、对旧数据过期,以及其他查询功能(例如,高效的近似函数和额外的时间序列函数)
- Ad-hoc:YouTube 的各个团队需要执行复杂的临时分析,以了解使用趋势并确定如何改进产品,这需要对海量数据(数万亿行)进行复杂查询(多级聚合、集合运算、分析函数、join,不可预测的 pattern,操作嵌套/重负数据等),查询量不是很大(每秒可能几十次),延迟适中(几秒到几分钟),查询模式高度不可预测,但是可以用类似 star/snowflake schema 进行建模
独立系统的问题
- 需要用 ETL 在多个系统之间进行同步数据,导致资源浪费,数据质量/数据一致性不好保证,数据延迟,以及维护性的增大
- 不同的系统使用不同的 API,甚至不同系统的 SQL 语法都不完全一致,导致数据的访问困难
- YouTube 的数据规模太大,部分组建无法满足需求(性能,扩展性,效率等)
Procella 的特性
- 丰富的 API,支持几乎完整的标准 SQL,并提供多种实用的扩展,例如近似聚合、处理复杂的嵌套和重复模式、UDF 等
- 高扩展性,支持存算分离
- 高性能:每秒数百万次查询,支持毫秒级的延迟
- 数据新鲜度:支持 batch & streaming 模式下的高容量、低延迟数据读取,能够直接处理现有数据,原生支持 Lambda 架构
- Procella 使用了轻量级的 zonemaps, bloom filters, partition 以及 sort key 等二级索引,而不是 BTree,二级索引从文件头、或者 plan 的时候从 data server 获取,schema、table->file mapping, stats 以及 zonemap 这些存储在 BigTable/Spanner 中
架构如下所示
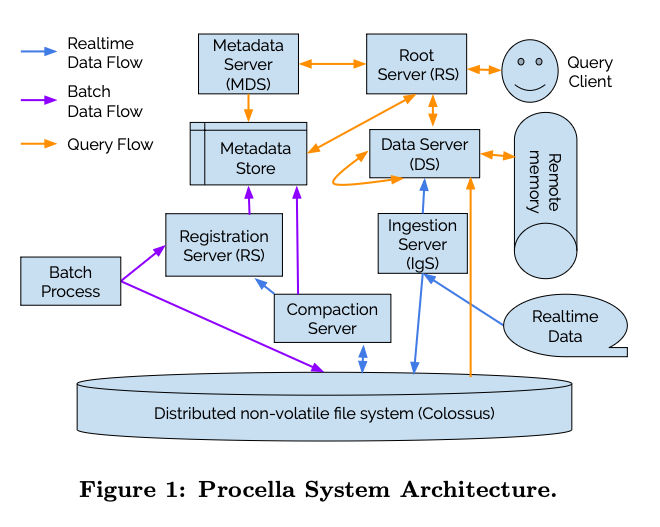
Procella 有一些优化
Cache
- metadata caching 可以减少文件访问
- Header cache,减少文件访问,header 有 start offset, column size, minimum and maximum 等信息
- Data Cache(在 Data Server 上) Procella 的 file format 是 Artus,disk 和 memory format 一致,这样对 cache 更友好,同时也缓存一些二级数据(比如 bloom filter 等)
- 亲和性调度,这样可以让 cache 更高效,但是这个亲和性不是强约束(如果没有满足的也可以调度到其他 server)
DataFormat
- 一开始用 Capacitor,但是它主要面向 Ad-hoc(主要是 scan 场景),Procella 需要 lookup 和 range scan,所以开发了 Artus
- 使用自定义的 encoding,这样可以在不反序列化的情况下定为到某个 row,对 point lookup 和 range scan 更友好
- 通过多轮自适应的 encoding 找一个更合适的 encoding,第一次会收集 ndv, min, max, sortorder 等信息
- 选择对 sorted column 支持 binary search 的 encoding
- 嵌套字段的处理和 parquet 不一样,把表的 schema 当作 tree,每个字段都存在为独立的列,针对每个父子段(如果自己本身存在的话),会记录所有字段出现的次数,对于可选字段,该值是 0 或者 1,重复字段该值为非负,但是不记录父字段不存在的信息(we visualize a table’s schema as a tree of fields. We store a separate column on disk for each of these fields(unlike rep/def, which only stores leaf fields). When ingesting a record, each time a parent field exists, we note thte number of times each of its children occur. For optional fields, this is either 0 or 1. For repeated fields, this number is nono-negative.
- Directly exposes dictionary indices, Run Length Encoding information, and other encoding information to the evaluation engien.
- Records rich metadata inthe file and column header.
- Supports storing inverted indexes
支持 multi-level partitioning and clustering
Join 的解决
- Broadcast: 一方足够小可以加载到 DS 的内存
- Co-partitioned: fact 和 dim 可以使用同样的 key 进行 partition
- Shuffle: 数据太大,然后没有按照 join key 进行排序
- Pipelined:RHS 是负责查询,但是结果可能比较小的时候
- Remote lookup: dim table 是分区的,但是 fact 没有
怎么解决 tail latency
- 因为数据有多备份,如果某个数据节点的访问延迟超过了中位数(median),会访问其他的节点
- RS 会控制访问同一个 DS 的频率,批次等
- RS 会被每个请求附带一个优先级,通常来说小查询的优先级更高,大查询的优先级更低,DS 为高优和低优查询分别分配资源,这样可以保证小查询快速响应 — 不会被大查询 block
Intermediate merging
- 对于部分大查询,最后的 merge 会成为瓶颈 — 因为需要节点 merge 很多数据。为了避免这个,添加中间节点来做中间的聚合。
Query Optimization
Virtual Tables(类似 MV)- The core idea is to generate multiple aggregates of the underlying base table and choose the right aggregate at query time(either manually or automatically).
Procella virtual table implementation supports:- Index-aware aggreagte seletion, choose the right table(s) based not just on size but also on data organization such as clustering, partitioning, etc. by matching the filter predicates in the query to the table layout, thus, minimizing data scans.
- stitiched queries, stitch together multiple tables to extract different metrics from each using
UNION ALL, if they all have the dimensions in the query. - lambda architecture awareness, stitch together multiple tables with different time range availabilites using
UNION ALL. This is useful for two purposes. First, for stitching together batch and realtime data where batch data is more acurate and complete, but arrives later than realtime data. Second, for making batch data consistently available at a specific cutoff point sooner by differently available at a specific cutoff point sooner by differentiating between batch tables that must be available to cover all dimension combinations vs. ones that are just useful for further optimization. - join awarenesss: The virtual table layer understands star joins and can automatically insert joins in the generated query when a dimensional attribute is chosen that is not de-normalized into the fact table.
Query optimizer
Procella has a query optimizer that makes use of static and adaptive query optimization techniques. At query compile time we use a rule based optimizer that applies standard logical rewrites (always benefical) such as filter push down, subquery decorrelation, constant folding, etc. At query execution time we use adaptive techniques to select/tune physical operators based on statistics (cardinality, distinct count, quantiles) collected on a sample of the actual data used in the query.- Adaptive Aggregation
- Adaptive Join
- Adaptive sorting
Adaptive 的不足:需要动态收集信息,可能导致短查询耗时更久(比如 10ms左右的查询最终耗时变成原来的数倍),这种可以让用户给定 hint 不走 adaptive optimization,另外用户愿意接受短查询变长来换长查询耗时的变短(overhead可能有 10% 左右)
针对 servering 做优化处理
- 数据写入后,会立即通知 dataserver 进行加载,这样避免冷读
- MDS 编译进 Root server,减少 RPC 交互
- metdata 提前加载到内存
- query plans are aggressively cached to eliminate parsing and planning overhead. This is very effective since the stats query patterns are highly predicatble.
- The RS batches all request for the same key and sends them to a single pari of primary and secondary data server.
- The problematic outlier tasks are automatically moved to other machines.
Pipelined SQL
最终用户侧的接口还是使用 SQL,但是 SQL 会遇到问题(比如嵌套 SQL,调试等),因此提出了 PipelinedSQL。
SQL 提供了一个很好的抽象,但学习和维护不太方便,重新造一个类似 SQL 又很麻烦,PipelinedSQL 是一个渐进式的改进方案。PipelinedSQL 可以让 SQL 更好用,更具扩展性(more flexible, extensible and easy to use).
- SQL’s foundational semantics, from relational algebra, are excellent
- SQL’s conceptual data model and top-level syntax, with statements representting requires, DDL, DML, etc, and composability via subqueries, works weel.
- SQL’s basic operations within a query(clauses like JOIN, ORDER BY, etc) all work reasonably well
- SQL’s syntactic structure for composing queries using those operations is terrible.
- SQL’ls localized syntax with English-like keyword phrases is and anachronism, but we can live with it.
- SQL’s expression language is fine, and implementations typically includes a good library of existing functions.
因此只需要修复第四条即可,PipelinedSQL 就是为了修复第四条而生的
给了两个例子1
2
3
4
5
6
7
8
9
10SELECT c_count, COUNT(*) AS custdist
FROM
(SELECT c_custkey, COUNT(o_orderkey) c_count
FROM customer
LEFT OUTER JOIN orders ON c_custkey = o_custkey
AND o_comment NOT LIKE '%unusual%packages%'
GROUP BY c_custkey
) AS c_orders
GROUP BY c_count
ORDER BY custdist DESC, c_count DESC;
Pipelined SQL 的写法如下所示1
2
3
4
5
6
7
8FROM customer
|> LEFT OUTER JOIN orders ON c_custkey = o_custkey
AND o_comment NOT LIKE '%unusual%packages%'
|> AGGREGATE COUNT(o_orderkey) c_count
GROUP BY c_custkey
|> AGGREGATE COUNT(*) AS custdist
GROUP BY c_count
|> ORDER BY custdist DESC, c_count DESC;
下图是 SQL 和 PipelinedSQL 的语义情况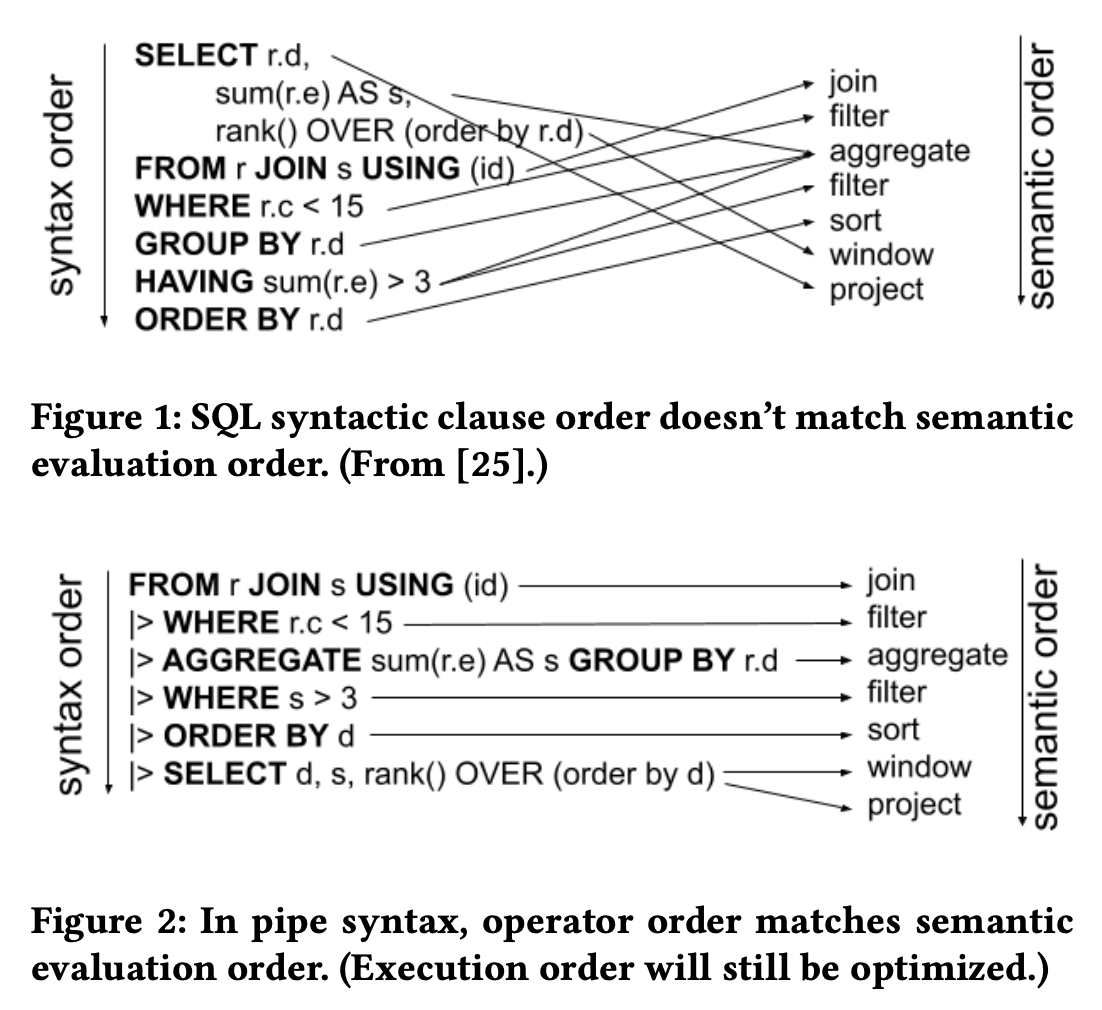
其他
本文中的 FileFormat,TableFormat,Metadata Service,Optimizer Service,QueryEnginge 等一起组成了一个多模态数据的处理系统,数据类型上支持结构化,半结构化和非结构化的数据,流程上包括了数据的全生命周期(ingest,optimize,query)流程。由于论文都是 Google 发布的,相关系统并未开源,好在现在我们可以在开源界中可以找到相关可以替代的系统,通过将开源系统进行组装,修改达到同样的效果。
Ref
[1] Vortex - A Stream-oriented Storage Engine For Big Data Analytics
[2] Big Metadata - When metadata is Big Data
[3] Napa-Powering-Scalable-Data-Warehousing-with-Robust-Query-Performance-at-Google
[4] Progressive Partitioning for Parallelized Query Execution in Google’s Napa
[5] BigLake - BigQuery’s Evolution toward a Multi-Cloud Lakehouse
[6] Procella - Unifying serving and analytical data at YouTube
[7] SQL Has Problems. We Can Fix Them: Pipe Syntax In SQL
[8] ClickHose - Lightning Fast Analytics for Everyone https://www.vldb.org/pvldb/vol17/p3731-schulze.pdf