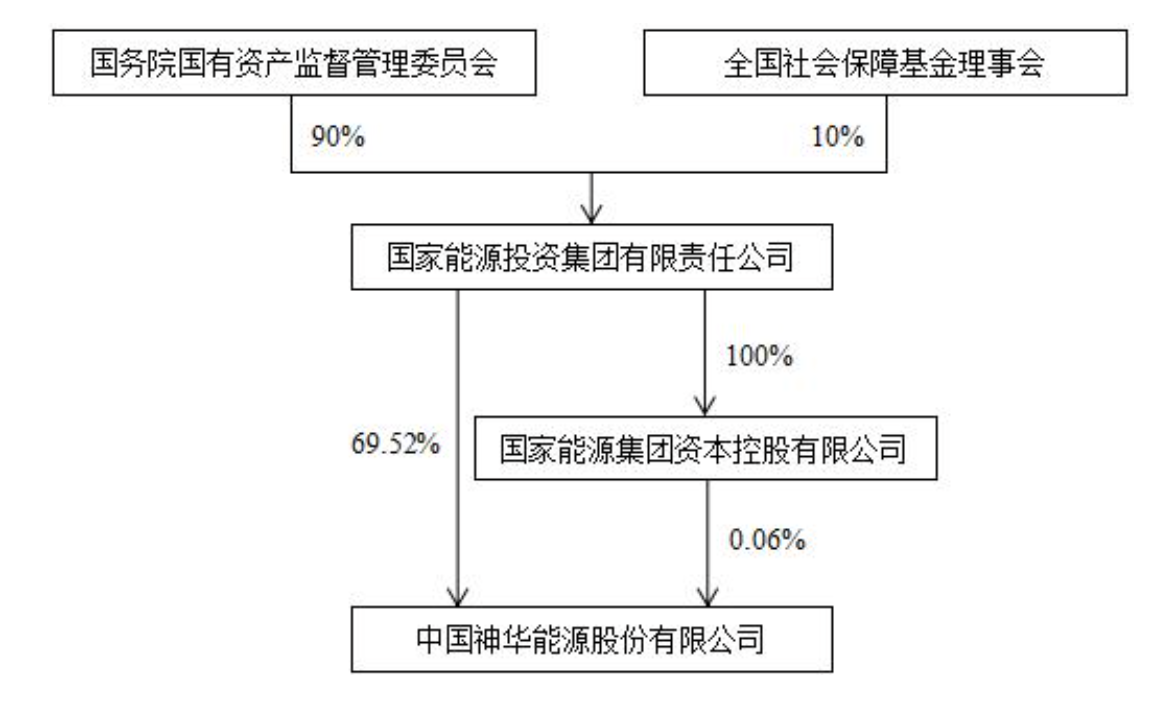
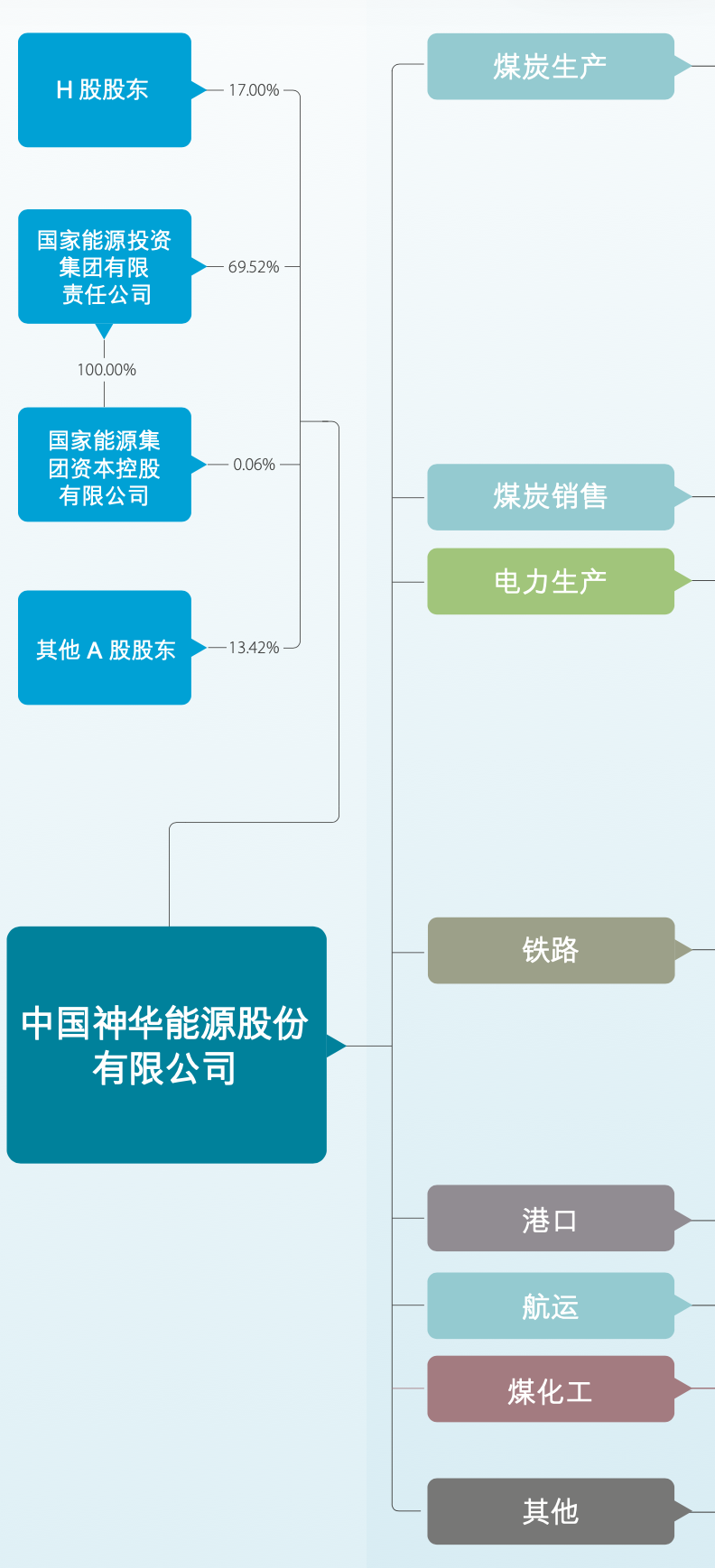
AI 发展越来越快,人是否会被 AI 替换掉,如何评估 AI 的能力以及和 AI 相处。现在 AI 发展很快,这是一个阶段性的思考,主要用作记录备份,供后续 review 使用。
最近几年 AI(这里特指以 Transformer 为主的 LLM)发展越来越快,不时会有一些说法:(某些岗位的)人大概还有多久会被替代?
这个问题包含了至少两层意思:
- AI 完全替代所有(该岗位)的人
- 使用 AI 的人替代了不使用 AI 的人
AI 发展越来越快,人是否会被 AI 替换掉,如何评估 AI 的能力以及和 AI 相处。现在 AI 发展很快,这是一个阶段性的思考,主要用作记录备份,供后续 review 使用。
最近几年 AI(这里特指以 Transformer 为主的 LLM)发展越来越快,不时会有一些说法:(某些岗位的)人大概还有多久会被替代?
这个问题包含了至少两层意思:
茅台 2025 年年报出来后,股价下跌 3.8%,茅台还值得投资吗?投资到底在投什么?怎么赚超额收益?
| 指标 | 2025 年 | 2024 年 | 本期比上年同期增减(%) | 2023 年 |
|---|---|---|---|---|
| 营业收入 | 168,838,102,514.79 | 170,899,152,276.34 | -1.21 | 147,693,604,994.14 |
| 利润总额 | 114,755,261,605.08 | 119,638,578,194.46 | -4.08 | 103,662,553,689.81 |
| 归属上市公司股东的净利润 | 82,320,067,101.68 | 86,228,146,421.62 | -4.53 | 74,734,071,550.75 |
| 归属于上市公司股东的扣除非经常性损益的净利润 | 82,293,107,655.25 | 86,240,905,977.42 | -4.58 | 74,752,564,425.52 |
| 经营活动产生的现金流量净额 | 61,522,204,989.35 | 92,463,692,168.43 | -33.46 | 66,593,247,721.09 |
| 归属于上市公司股东的净资产 | 244,637,811,032.18 | 233,105,984,399.47 | 4.95 | 215,668,571,607.43 |
| 总资产 | 303,834,844,021.44 | 298,944,579,918.7 | 1.64 | 272,699,660,092.25 |
| 基本每股收益 (元/股) | 65.66 | 68.64 | -4.34 | 59.49 |
| 稀释每股收益 (元/股) | 65.66 | 68.64 | -4.34 | 59.49 |
| 扣除非经常性损益后的基本每股收益 (元/股) | 65.64 | 68.65 | -4.38 | 59.51 |
| 加权平均净资产收益率 (%) | 32.53 | 36.02 | 减少 3.49 个百分点 | 34.19 |
| 扣除非常性损益后的加权平均净资产收益率 (%) | 32.52 | 36.03 | 减少 3.51 个百分点 | 34.20 |
本文尝试从 Google 发表的部分论文看一个可能的多模态 Data Infra 系统, 包括数据的写入、存储、管理&优化 和查询,支持多模态(结构化、半结构化和非结构化数据)。相关思想也可应用在以开源组件为基础的系统上。
这里的多模态数据湖系统包括数据的写入,存储,管理(&优化),以及查询,并且包括全链路的权限管理等,支持跨云跨域的操作。同时给用户一定的灵活度,可以在不同的场景下选取最优的方案。
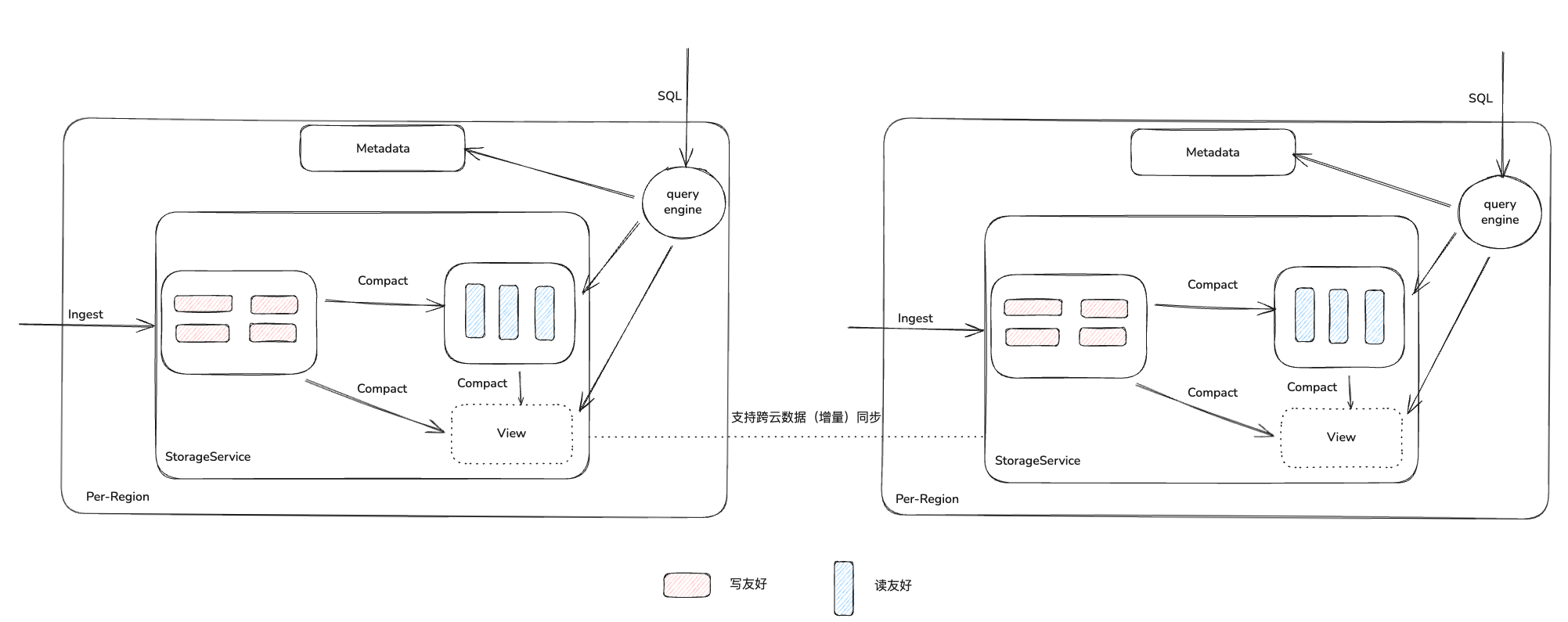
一个简化后的系统图如上所示,下文会分模块来介绍
本文尝试记录一些茅台公司的基本情况,便于对公司的深入了解。
茅台的香型有三种典型体 — 酱香,窖底香,醇香。茅台酒命名为酱香型。[1]
在分析场景下列存相对行存有非常大的优势,可以极大减少 IO 的开销。在 Data Page Layouts for Relational Databases on Deep Memory Hierarchies[1] 一文中,引出了 PAX 格式并与行存进行了对比。
以下表数据为例
| column_a | column_b | column_c |
|---|---|---|
| 1 | abcd | 3.2 |
| 2 | efdf | 4.7 |
分别使用行存和列存写到磁盘后的格式大致如下
为了较好展示,以
,为分隔符,且省略了各种 header/footer
| 存储格式 | 内容 |
|---|---|
| 行存 | 1,abcd,3.2,2,efdf,4.7 |
| 列存 | 1,2,abcd,efdf,3.2,4.7 |
在分析场景中,读取某一列所有的数据是常见操作,但是对于行存来说读取某一列数据,需要在文件中进行多次 IO 定位,然后读取值,而对于列存来说可以直接顺序的读取某列整体的值。比如上述示例中读取 column_c 的值
在行存中需要
在列存中需要
连续读取的开销比随机读取少,也就是第二种的开销更小,因此列存在分析场景中开销更小。
文献[1] 中描述列存格式可以比行存减少由于 cache miss 导致的停顿延时 75%;range selection 的查询可以快 17-25%,TPC-H 中 I/O 更重的 query 要快 11-48%。
交易市场往往在大幅波动(大涨/大跌)的时候会比较活跃,最近市场行情不错,整体活跃度增长,这里记录下自己当前关于价值投资的一些看法。值投资价值投资的好处:比较大概率能赚钱(逻辑通顺),主要依赖自己下的功夫,不需要一直盯盘(投入时间不一定少,但是不那么急迫),最近 2972 天的复合年化 22.03% ,基本没有盯盘,整体效果还不错。
所有的投资都是一种 套利,价值投资则是在有价值的资产上以较低价格买入,然后等升值后卖出赚钱。因为在投资之前就已经进行了重复的计算,因此投资过程相对简单,但是简单并不表示容易:1)什么是有价值的资产:2)什么时候是(较)低价:3)如何能做到不受波动影响。每一步都不容易,但是做到一次之后就会越来越容易,而且这个会有复利
尝试记录一个思想快照,供后续 review 使用。
Arbitrage is the practice of taking advantage of a difference in prices in two or more markets – striking a combination of matching deals to capitalize on the difference, the profit being the difference between the market prices at which the unit is traded. Arbitrage has the effect of causing prices of the same or very similar assets in different markets to converge.
套利(Arbitrage): 是一种利用资产在不同市场/不同形态进行交易获取价差来获利的行为。这里的描述中更多的是空间上的,而没有描述时间上的。加上时间维度,就变成了二维空间(时间和空间),套利行为则是在二维空间中某两个(或多个)点之间赚取利差。前面的套利则是时间(基本)一致的情况下。
本文记录 Arrow-RS 中一次性能优化的情况。
最近尝试在 Arrow-rs 中做一些贡献来更好的学习了解下 Arrow 和 Rust。本文的事情则是在为 Arrow-rs 支持 parquet variant 中的一个修改。当前实现的过程中,Object 和 List 会创建临时 buffer,然后在最终 copy,这样会有一定的性能损失(主要在于临时 buffer 的创建以及拷贝),希望有一种方案能够直接写入到目标的 buffer 而不需要进行拷贝,也就是 ARROW-RS-7977 所记录的事情。
茅台股价和批价齐跌,作为股民我该怎么办?
最近(一年)茅台股价下跌,加上现在批价下行,作为茅台股民我该怎么办呢?
这个时候作为股民应该感到高兴,理由有几:1)股价下跌,导致入场成本低;2)批价下跌,会影响股价向下,转到第一点;3)股价/批价不影响茅台公司的盈利能力。