columnar-file-formats
Background
在分析场景下列存相对行存有非常大的优势,可以极大减少 IO 的开销。在 Data Page Layouts for Relational Databases on Deep Memory Hierarchies[1] 一文中,引出了 PAX 格式并与行存进行了对比。
以下表数据为例
| column_a | column_b | column_c |
|---|---|---|
| 1 | abcd | 3.2 |
| 2 | efdf | 4.7 |
分别使用行存和列存写到磁盘后的格式大致如下
为了较好展示,以
,为分隔符,且省略了各种 header/footer
| 存储格式 | 内容 |
|---|---|
| 行存 | 1,abcd,3.2,2,efdf,4.7 |
| 列存 | 1,2,abcd,efdf,3.2,4.7 |
在分析场景中,读取某一列所有的数据是常见操作,但是对于行存来说读取某一列数据,需要在文件中进行多次 IO 定位,然后读取值,而对于列存来说可以直接顺序的读取某列整体的值。比如上述示例中读取 column_c 的值
在行存中需要
- 定位到 3.2 的位置
- 读取 3.2 的值
- 定位到 4.7 的位置
- 读取 4.7 的值
在列存中需要
- 定位到 3.2 的位置
- 连续读取 3.2 和 4.7 的值
连续读取的开销比随机读取少,也就是第二种的开销更小,因此列存在分析场景中开销更小。
文献[1] 中描述列存格式可以比行存减少由于 cache miss 导致的停顿延时 75%;range selection 的查询可以快 17-25%,TPC-H 中 I/O 更重的 query 要快 11-48%。
Apache Parquet
现在工业界中的列存格式大部分场景都会使用 Apache Parquet[2] 或者 Apache ORC[3]。由于数据湖格式的兴起,Apache Iceberg/Delta 等均以 Apache Parquet[2] 为主要格式,其他一些分析型 DB 重点支持 Apache Parquet,Apache Parquet 基本成为工业界列存的事实标准。
Apache Parquet 定义了一套语言无关的规范,不同语言基于同一套规范进行开发。定义大致如下
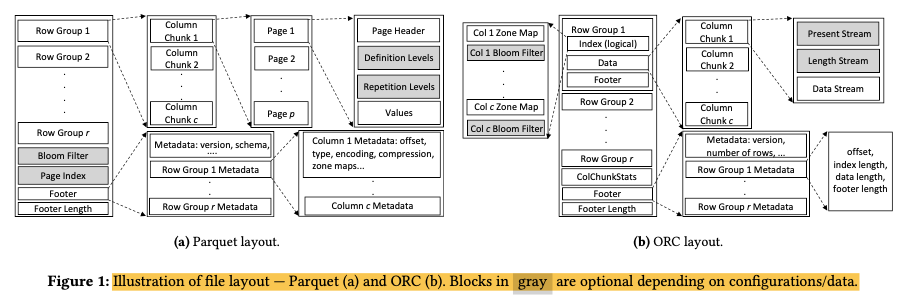
Parquet 的读写流程大致如下
- 写入
- 将数据写入内存并记录相应的 stat
- 待数据足够大(满足一个 row group 大小)后写出到磁盘,并重复该步骤
- 整个文件写完(主动或触发条件)写入可选信息(ColumnIndex/OffsetIndex/BloomFilter 等)
- 写出整个 footer 完成文件的写出
- 读取
- 读取 footer 信息
- 解析 footer 信息中的 column metadata(使用 Thrift 所以需要进行全部读取和解析)
- 使用 column metadata 中的 stat 对数据进行过滤 (如果有 ColumnIndex/OffsetIndex 可以读取并进行更精细的过滤)
- column 级别的信息是 row group 中 column 级别的信息
- columnIndex/offsetIndex 则是 column 中 page 级别的信息(如果没有 columnIndex 则需要读取 PageHeader 才能对 Page 进行过滤,PageHeader 保存在 Page 内部)
- 定位到对应的 offset 读取实际的 page
- 读取并反序列化 page 的内容
- 对内容进行过滤
- 读取 footer 信息
从读写流程可知
- 写入
- 需要 buffer 整个 row group 然后整体写出, 因此:1)写入端需要较多内存;2)列的大小差异较大会导致部分列存储的数据量少,从而影响读取时的 IO (多次小 IO)。
- 读取
- 对于列非常多的情况下,读取和反序列化 columnChunkMetadata 可能开销较大(部分列实际不需要,但必须要读取),在没有 ColumnIndex 的情况下,stat 信息过滤的粒度太粗,且需要读取 page header 才能对 page 进行过滤(page header 和 page data 存放在一起)
- 对于嵌套列(Map/List)读取不太友好(比如读取 Map 中某个 key)
由于现在 AI 场景中对于宽表(列比较多)和宽列(以及嵌套列)比较多,因此问题会更突出。现在工业界和学术界都有想办法进行改进和优化。
Another FileFormat or Better Parquet
对于解决 Parquet 的劣势场景,主要有两个方向:1)是造一个新的 file format;2)在 Parquet 的基础上进行迭代优化。
其中前者出现了 Nimble/Lance/Vortex 等一系列 format; 后者包括 Parquet Variant[4], 优化 footer 的读写[5][6],以及在 Parquet 之上增加纯内存的 format 作为 cache 等;
Another FileFormat
从零开始构造一个新的 file format 满足更多的场景以及硬件是一个很直观的想法,大公司和初创公司出现较多,Google/Meta 等有自己的列存格式,Goolge 的没有开源,Meta 的 Nimble[7] 已经开源;初创公司现在有 Lance[8]/Vortex[9] 是两个新兴的 file format。Lance 由于字节在推动知名度更高一些。Lance 和 Vortex 在 IcebergSummit 2025 上也有一个相关的 talk[10]。
Lance
从 Lance 官网[11] 可知,Lance 的结构大致如下
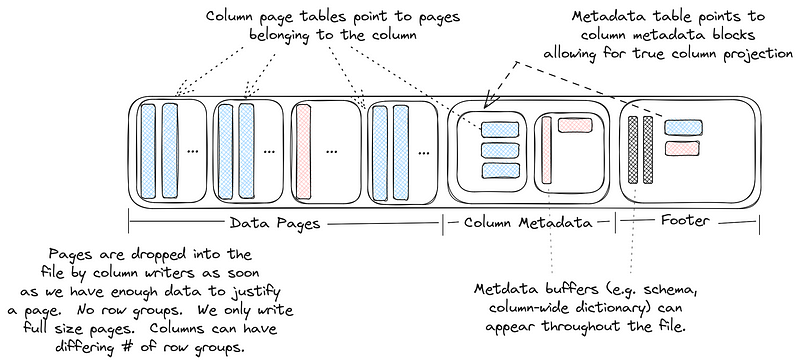
Lance 以一种更扁平的方式存储文件,没有 Parquet 中的 row group 的概念,数据会包括多个 page,每列的 page 写满后即可落盘,每个 page 会包括多个 buffer。ColumnMetadata 中会记录每个 buffer 的信息,然后也会记录 Global 的 Buffer 信息(全局的信息),最终的 Footer 会记录 ColumnMetadata 的相关信息(offset/size 等)以及一些其他类似版本,校验字等信息。
从格式可以知道
- 写入的时候不需要 buffer 整个
RowGroup信息,因此内存消耗会小一些 - 随机读取的时候因为有更细粒度的 stat 和索引,所以查询会更快一点(对于定长的数据,甚至可以直接通过计算定位到具体的 row)
另外 Lance table format 有一个很有意思的点, 提供了 fragement: 一个 fragement 可以包括多个文件,这些文件的数据可以属于不同的列。这样可以在不重写数据的情况下支持动态增加列,并给存量数据的新列加上值。这在需要频繁加列的情况下会很友好,不过这个属于 table format 的层面,也就是说其他像 Iceberg/Delta 等也可以支持。
Vortex
Vortex 的结构大致如下
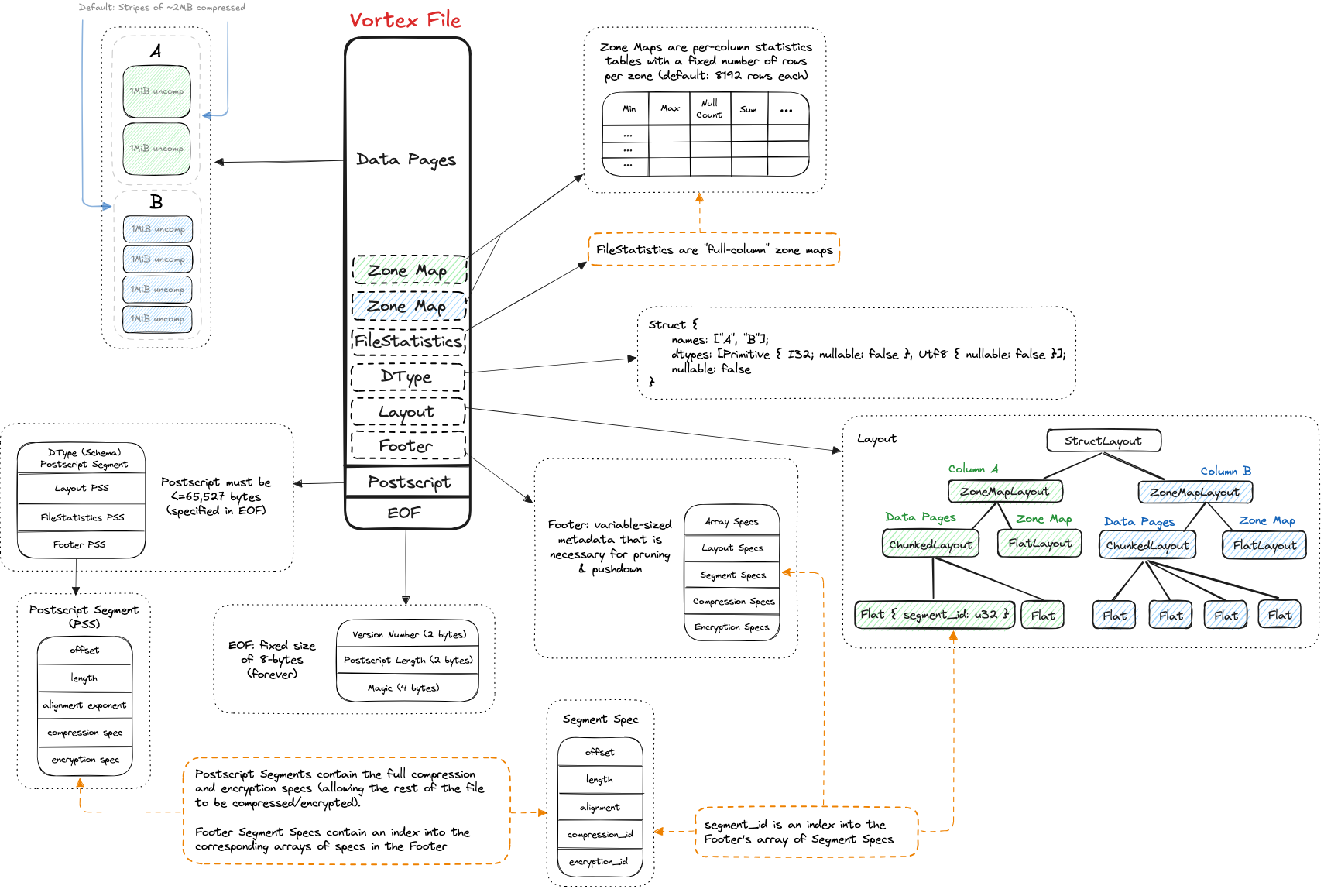
- DataPages 记录了具体的数据
- Zone Map 记录某一列多行(逻辑 row group)的 stat,比如 min/max/nullcount 等
- Filestatistics 记录文件级别的列 zonemap
- Dtype 则是文件的逻辑数据类型(类似业务视角的数据类型),也就是 schema
- Layout 是文件的存储格式,比如文中可以理解为和 Parquet 类似的一个存储
- Footer 记录一些可以用来做过滤的信息
Postscript 记录了 schema/layout/filestatistics 以及 footer 信息,每个信息都是一个 segment(包括 offset, length, alignment exponent, compression spec, encryption spec 等)
写入
- Vortex 内 row group 更多的是一个逻辑概念,写入不需要 buffer 整个 row group 的内容,因此内存消耗比 Parquet 也会更小。
- 读取
- Vortex 首先读取 footer 创建 reader,然后可以通过 zonemap 中的信息进行过滤,然后从剩下的 segment 中进行读取(可以通过 segmentId 直接定位到文件中的 offset 继续读取),然后反序列化后进行更细的过滤。
- 对于嵌套类型(Struct),可以使用不同的 Layout 将内部数据拆开,比如上图中的 Struct 两列 Column_A 和 Column_B 可以分开存储,这样读取的时候,仅需要读取某一列,而不是整个 Struct。
由于 Vortex 将逻辑数据和物理存储拆开,因此可以同样的逻辑数据使用不同的物理存储,这样也可以支持在压缩数据上进行一定的计算与过滤。Vortex 中数据类型有 Owned 和 Viewed 两种,Owned 表示内存上的数据,Viewed 则表示磁盘上数据的视图,这样可以按需加载。
Better Parquet
Parquet 拥有一个不错的生态,在生产环境中要从一个成熟的生态中迁移是一件较难的事情,因此在 Parquet 基础上进行迭代改进也是一个方向,包括 Variant 以及 footer 读取的优化等。
Variant
Paruqet 的 Dremel 类型对存储量更优化,但是对于 CPU 计算和内存向量化(读取吞吐)等则不那么友好
比如在 paruqet 中读取 nested data 的时候, 需要
- 根据 repetition level 和 definition level 重构整个数据
- Filter 支持不好,因为 Parquet 的 stat 经常是 RowGroup 或者 Page 级别的,无法对 inner data 进行过滤
- SchemaEvolution 支持不好
- 不太好支持 SIMD
现在 Parquet variant 的出现则希望解决这一问题: Variant 默认将所有数据存储到一个二进制数组中,且包括一个 metadata,这样形成自解释的数据结构,同时可以将部分数据从二进制数组中抽出来单独存储成一个物理列,这样可以更好的进行计算和过滤。
Variant 大致如下所示,其中 metadata 用于解释当前 variant,value 包括了所有非进行 shred 的二进制数据,typed_value 则存储了实际被抽出来的子列。更具体的可以参考 VariantShredding[12]1
2
3
4
5- metadata
- value
- typed_value
- [value]
- [typed_value]
这样操作之后
- 可以很好的支持 SchemaEvolution
- 数据访问的时候,可以使用 stat 进行过滤(因为单独抽出来一列,有 stat 信息);可以使用 SIMD 操作(因为单独一列存放在一起)
Cache & MemoryFormat
Parquet 是一个非常成熟,拥有良好生态的 format,所以改动会相对缓慢,因此有人提出在 Parquet 之上搭建一套纯内存的 file format, 这个 file format 相比 Parquet 更适合使用在 cache 场景,这就是 LiquidCache[13] 的想法, Cache 中存储的是“逻辑数据”,而不是原始的 Paruqet 文件,主要考虑是:纯内存的 file format 可以比 Parquet 更适合 cache,且更自由的进行更新迭代(升级成本低);可以复用现有 Parquet 的整体生态。
直接 cache Parquet 格式本身,然后进行 filter pushdown 可能无法提升速度,反而会导致速度下降,主要原因在于 Parquet 的主要开销是 decode 和 decompress(超过 90%),而 Parquet 本身也不好针对 filter pushdown 做优化。文中描述了将物理结构与逻辑结构进行解耦,这样 LiquidCache 可以将 Parquet 转换成 liquid format。Liquid format 结合了 selective decoding,late filter materialization 以及 endocing-aware predicate evaluation,可以比 Parquet 更好的支持 filter pushdown。Parquet 转换为 liquid format 则是异步进行的,可以不 block 正常的处理流程。
LiquidFormat 相对 Paruqet 的优势可以从下面两种图中可以查看
下图中 LiquidFormat 可以比 Paruqet 少 decode 数据(只需要 decode 实际命中的数据)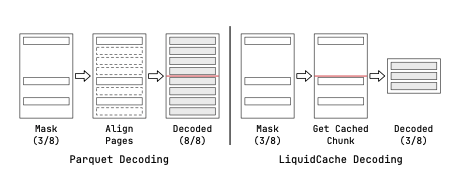
下图中则是 liquid format 在多 filter 场景下,可以应用 late materialization,在前面 filter 处理后的数据上进行 decode,这样可以减少第一个 filter 中被过滤掉数据的 decode。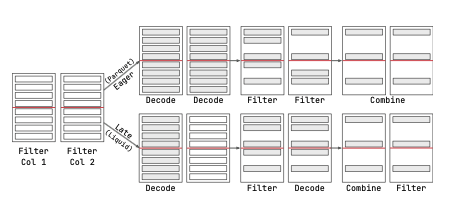
文中有给一些结论,整体来说 liquidcache 拥有不错的性能,更详细的数据可以参考原文以及 Github 仓库
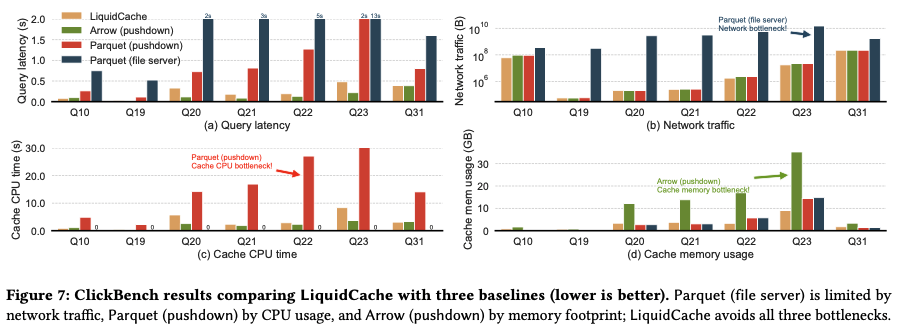
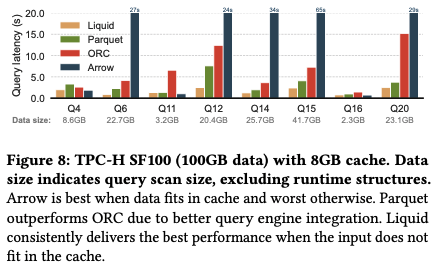
Column File Format in Academic
学术界也有关于列存的研究[14][15]. 其中文献[14] 对列存进行了对比,文献[15] 则提出了一种新的列存 F3,并和已有的列存进行了对比,虽然学术界到工业界落地可能需要一段时间,但是其思路是可以参考的。
Compare between column file formats
本文[14] 设计了一个 benchmark 并以 Parquet 和 ORC 为例进行了对比。
Benchmark 中引入了数据分布的几个维度: NDV, NullRatio, ValueRange, Sorteness, SkewPattern 用来表示数据的不同维度。
论文中从 Public BI Benchmark/Clickhouse/UCI-ML/Yelp/LOG/Geonames/IMBD 多个数据集中进行分析得到如下分布情况
- 超过 80% 的 Integer,超过 60% 的 String NDV 小于 0.01, 超过 60% 的 float NDV 小于 0.1
- 也就是说 Dictionary Encoding 是有用处的
- Null 的数据比较多
- 大部分数据分布式不均匀,小于 5% 的数据是 Uniform,60-70% 的在 Gentle Zipf 分布
- file format 需要能同时处理热点数据和长尾数据
- 数据要么是完全排序的,要么就是无序的
- 对于有序的编码部分情况有用的
- 数据范围比想象中的要小
- 数值型的大小绝大部分在 1e4 以内(80%)
- String 80% 的长度小于 25, 60% 的长度小于 10, 90%+ 的长度小于 50
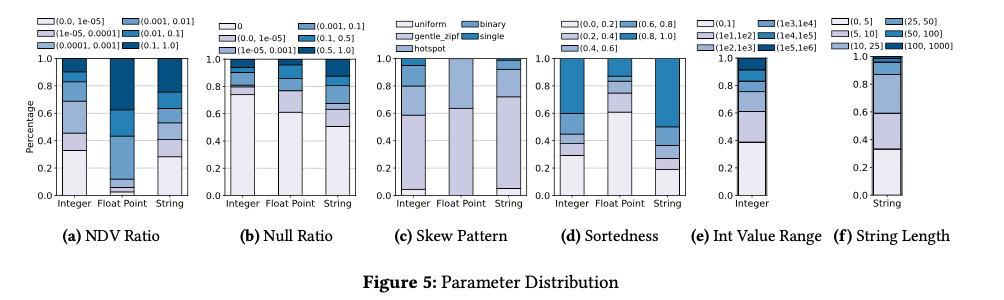
将相关数据分类后总结成如下表格
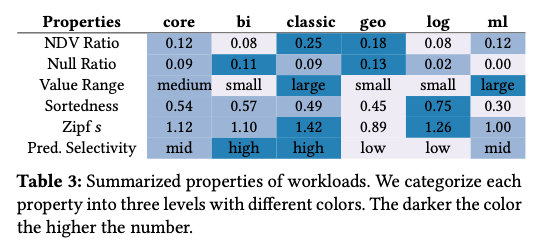
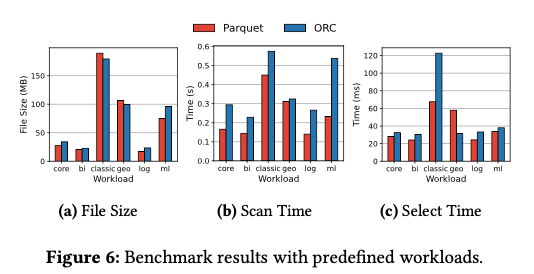
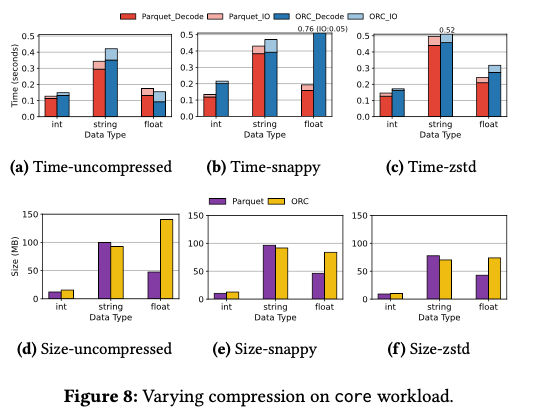
在不同场景下 Parquet 和 ORC 的对比如下(绝大部分场景相差不是很大)更详细的数据可以参考论文(从这里也能看出 Decode 比 IO 耗时更多)。
F3
本文认为已有的 format 诞生时的假设已经不成立
- 1 relative hardware performance
- 2 workload access pattern
主要原因在于
- 最近 10 年存储和网络性能有很大的提升,但是 CPU 的性能没有成比例的增长
- 数据湖的出现也让更多的数据存储在高吞吐高延迟的云存储中,也让整体瓶颈从 IO 转移到 CPU
- 数据的结构也发生了很大的变化(数据越来越”宽” — 表的列很多,以及列里面的数据可能很大 — 比如 blob),ML 场景下存储几千列的特征,以及高维向量、图片等 blob 数据已经变成越来越常见,同时应用也希望能够进行随机读取甚至对已有数据进行更新。
另外文中认为 Nimble/Lance/TSFile/Bullion/BtrBlocks 这些新的 format 也和之前的 format 有一样的问题: 对硬件和数据模式有一定的假设,就算取代了之前的 format, 在未来也会被新的 format 所取代。
F3 则是为了解决这些问题而诞生的,F3 的全称是 Future-proof File Format, 号称是下一代开源的 file format,拥有 interoperability,extensibility 以及 efficiency 等特性。
Eache self-describing F3 file includes both the data and meta-data, as well as WebAssembly(Wasm) binaries to decode the data.
F3 的整体架构如下所示
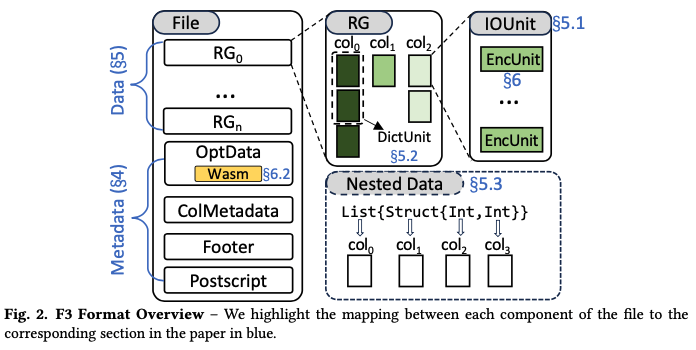
文件包括 Data 和 Metadata 两部分,其中 Data 保存数据,Metadata 保存元数据
Data 中的结构和 Parquet 类似,F3 的 RowGroup 是逻辑的,因为写入的时候不需要 buffer 整个 row group, 可以单独写某一个 IOUnit(对应 Parquet 中的 page),因此没有列大小不一样导致 IO 不是最优的情况。IOUnit 包括多个 EncUnit,EncUnit 是编解码的最小单元。EncUnit is essentially an opaque byte buffer that can be interpreted by the corresponding decoding implementation.
File Metadata 的结构如下所示
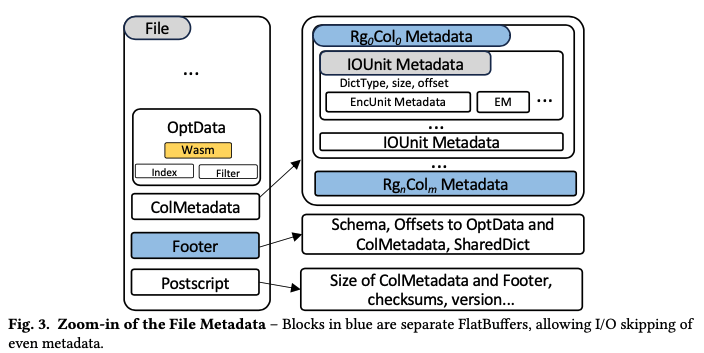
Metadata 包括 OptData/ColMetadata/Footer 以及 Postscript, 整体使用 flatbuffer 存储。其中
- OptData 是一个 keyvalue 的数据结构,现在用于存储 wasm binary (可以携带编解码逻辑),后续可以用来存储 index 和 filter 等
- ColMetadata 保存了每个 RG 中每个 column 的元数据(包括 offset/size, 以及 dictionarytype, size encoding method 等)这里也记录了类似 Parquet 中 page header 的信息,这样可以直接从 Metadata 中对数据进行过滤。
- Footer 记录 schema 以及 optData/ColMetadata/SharedDict 等的地址
- Postscript 记录 ColMetadata/Footer/checksum 等
在 F3 中 dictionary encoding 不像 Parquet 一样固定是 row group 级别,而是可以三类:None/Local/Shared。其中 None 表示没有 dictionary encoding,local 表示在当前 IOUnit 中,Shared 则表示可以和其他 IOUnit 共享(甚至跨 Column),这样可以有更好的灵活性。
对于 NestedData 的处理则使用 L&P 的格式(有 buffer 记录是否存在,然后其他的 buffer 记录具体的位置),右下角的形式
最后 F3 最后给出的一些不同 FileFormat 上的测试数据
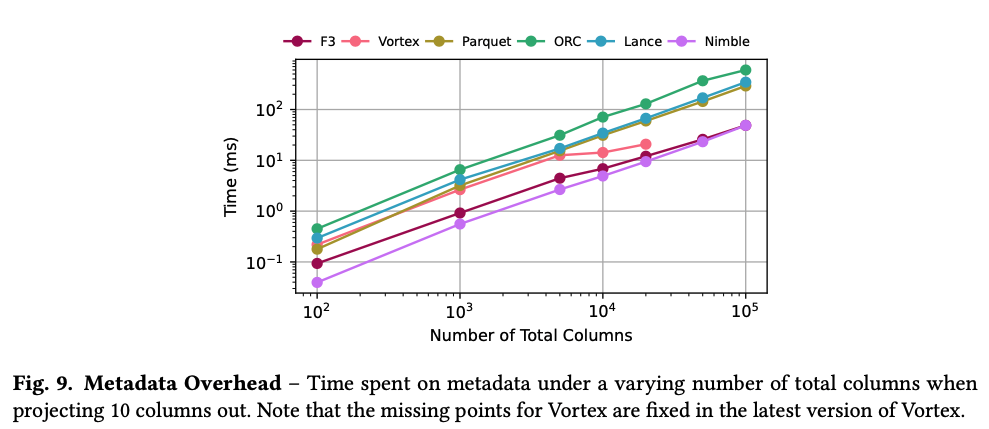
上图展示了随着列的增加,(所有 format)元数据的 overhead 基本是线性增长。因为不管 metadata 是否支持随机访问,在 footer 中均有与列大小正相关(比如 schema)的信息。Nimble 最快是因为存的信息最少;其他使用 FlatBuffer 但比 Nimble 慢的有一部分原因在于正确性校验; F3 比其他使用 FlatBuffer 的格式更好的原因在于支持跳过特定列的 I/O; Lance 需要读取和反序列化所有的 metadata,这也是导致它是所有使用 FlatBuffer 中最慢的;Vortext 可以跳过无关 metadata 的反序列化,但是无法跳过 IO。
文中的一些其他测试数据可以参考,更详细的可以参考原文
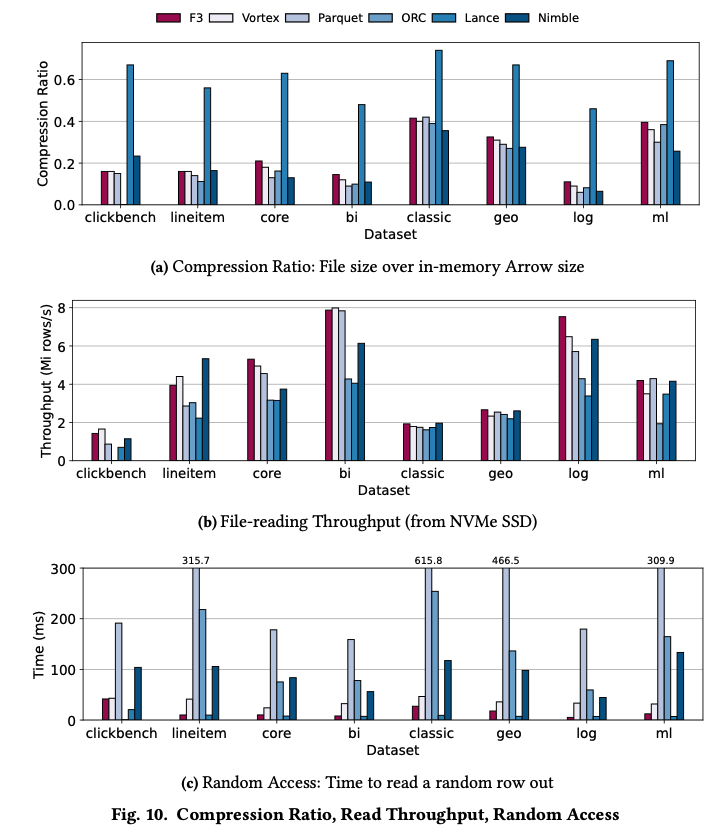
下图比较了不同 FileFormat 中压缩比、读吞吐、随机读延迟的情况。可以看出
- F3/Vortex 在所有的情况下都有不错的性能
- Parquet 拥有不错的压缩比,读取吞吐也不错,但是随机读性能差
- Orc 的压缩率不错,吞吐一般,随机读取的性能比较弱
- Lance 压缩率很差,读吞吐一般,随机读的能力很强
- Nimble 压缩率, 读吞吐和随机读大部分情况下都属于中等水平,少数情况下优秀
下图中上面的曲线表示不同的 row group size 情况下消耗的内存大小(左右是两个不同的场景). 其中 Parquet 对内存的消耗比其他的都要大; Lance 和 F3 都是以 IOUnit 为最小单位刷盘,因此消耗内存较小;Nimble 和 ORC 则控制了单个 row group 的物理大小, 但是这样会导致 row group 存储数据量较少;Vortex 则由 writer 控制 buffer 大小。
表格则表示不同的 FileFormat 的平均 ColumnChunk 大小,可以看到 ORC/Nimble 会有比较小的 ColumnChunk,Parquet 会有比较大的 Chunk,Lance 和 F3 的则会相对平均。

Conclusion
随着数据湖以及分析场景的广泛使用,列存的关注度也越来越高,如何在新场景,新硬件下拥有更好的性能,本文做了一些调研,总的来说 Parquet 在随机读取、SIMD 等方面较弱,其他的相对不错,这些可以有不同的优化方向;新的 FileFormat 则从不同的角度希望解决不同的问题。这些可以让我们在后续进行决策的时候提供一定的基础。
Ref
[1] Data Page Layouts for Relational Databases on Deep Memory Hierarchies
[2] https://parquet.apache.org
[3] https://orc.apache.org/
[4] https://github.com/apache/parquet-format/blob/master/VariantEncoding.md
[5] https://lists.apache.org/thread/j9qv5vyg0r4jk6tbm6sqthltly4oztd3
[6] https://arrow.apache.org/blog/2025/10/23/rust-parquet-metadata/
[7] https://github.com/facebookincubator/nimble
[8] https://github.com/lance-format/lance
[9] https://github.com/vortex-data/vortex/
[10] https://www.youtube.com/watch?v=p6ZKY8JViCA
[11] https://lancedb.com/blog/lance-v2/
[12] https://github.com/apache/parquet-format/blob/master/VariantShredding.md
[13] https://github.com/XiangpengHao/liquid-cache/blob/main/dev/doc/liquid-cache-vldb.pdf
[14] https://www.vldb.org/pvldb/vol17/p148-zeng.pdf
[15] https://db.cs.cmu.edu/papers/2025/zeng-sigmod2025.pdf