iceberg summit 2025 notes
本次 Iceberg Summit 2025[0] 上行业内众多公司做了分享,包括 Iceberg 核心技术、使用案例,优化方案,未来走向等等。其中国内的腾讯(两个 talk),小米,小红书均有分享,整体内容不错,这里做一个总结,更详细的请参考原视频。
Beyound Iceberg’s ongoing evolution
首先是 Iceberg 的 PMC member Ryan Blue 的 talk[1], 这个 talk 整体介绍了 Iceberg 的过去,现在以及将来的一些事情。Iceberg 现在已经成为湖仓的事实标准,在各大公司被官方使用,在湖仓一体/流批一体等方案中作为共享存储存在,提供了 ACID,time travel,branch,tag 等各种功能,支持了众多查询引擎,整体生态非常繁荣。
最近一年已经完成或者正在进行的一些重大特性包括
- Geo type 的支持,更好的支持地图数据
- Variant type 的支持,可以支持半结构化数据(这个另外一个 talk 单独有讲)
- 全表加密(data 和 metadata)
- deletion vector — 更好的 position deletes(有另外一个 talk 单独讲),在性能、文件数量以及维护成本做了一个均衡
- row lineage,主要方便增量消费以及数据的校验等
在 Iceberg 中增加新的数据类型可以带来:1)有标准,各引擎更方便交互;2)能够借用 Iceberg 的 Metadata/Index 等做查询优化。
另外在广泛使用过程中,大家也有提出来一些有关 metadata 的痛点,比如
- manifest 相关
- 文件可能会比较多:先生成 manifest 然后是 manifest list;manifest 会重写最后删除
- 现在对小表不太友好(实际中有很多小表):scan 需要走 manifest list 然后顺序的访问每个 manifest 文件
- manifest 文件太多:导致 metadata 需要周期性合并
- 故障恢复比较困难: file replication 不够恢复整张表;metadata 需要重写(主要是绝对路径)
- 列信息是二进制的:对扩展类型不优化(比如 geo/variant 等)
- plan 性能可以更好: 需要读取所有列信息(不在 filter 中的列信息也需要读取)
- Metadata skipping 需要分区信息:数据倾斜处理不好;无法和 geo 数据很好的结合;容易过度分区
针对这些问题,也有一些相应的规划,整体思路是 metadata 往 adaptive tree structure方向走,adaptive tree structure 加上 RestCatalog, 再加上 servcie 就更像 DB 了。
adaptive tree structure 大致如下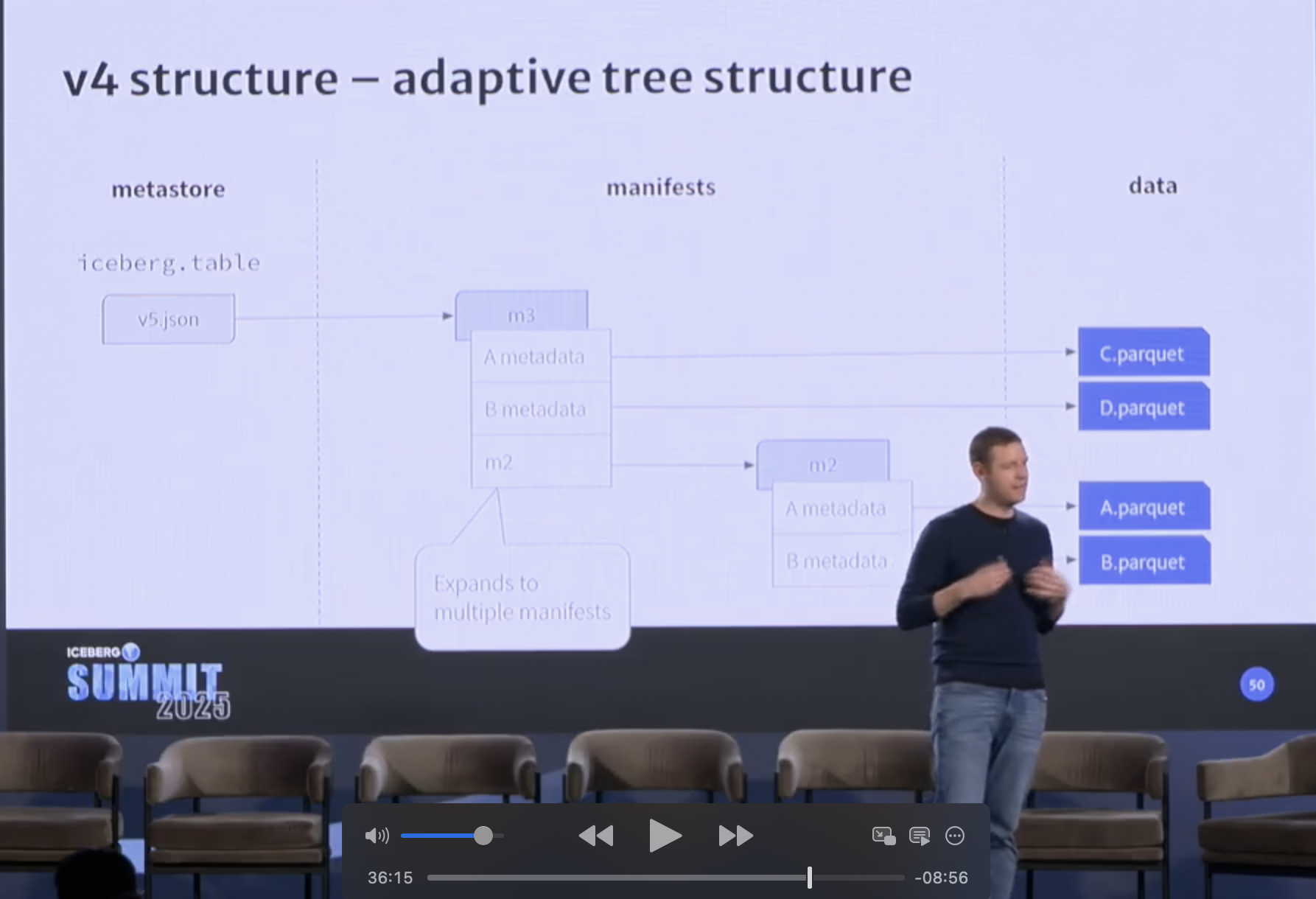
另外 Iceberg 也在如下一下方面有考虑
- Relative paths:主要是为了容灾、故障恢复考虑
- Columnar metadata: 更方便跳过不需要的 column stat;typed lower/upper bounds/alternative sort orders
- Adaptive metadata & Unified manifests: 更好的 manifest 结构,主要适配多模态数据,优化小表,manifest 的维护性等。
后文中会从如下几方面展开描述
- Manifest/Index:表元数据相关
- Catalog: Catalog 相关
- Compute&Management(Optimiztion&Service): 表查询和管理相关
- File format: file format 相关
- Streaming: 流式入湖
- Ecosystem(&usecase&migration): 生态以及迁移到 Iceberg
Matadata(manifest/Index)
Iceberg 的 metadata 是核心组件,包括了支持各种功能以及查询优化所必需的信息,这里介绍一些和 metadata 相关的演讲内容。更详细的可以查看原视频(下同)。
本次 Summit 中有介绍 Iceberg (正在)支持多种类型:geo 类型[2],variant 类型[3],支持了 deletion vector[4] — 更好的 position delete。
也有尝试将 Iceberg 的 metadata 暴露成常规的 Iceberg 表方便分析的[5],演讲中有介绍使用 PG 来承载 metadata 的分析,发现量大之后会遇到性能瓶颈,因此希望 Iceberg 原生支持将 metadata 暴露为标准表。
其中增加新类型主要是定义标准以及优化查询,geo 主要是地图相关的数据(点、线,区域等),而 variant 则主要是支持半结构化的数据 — 比如 json。variant 在 log/event 等数据类型中大量使用,IoT/Telemetry 数据非常多,variant 的支持还有一个就是增加 shredding 过程,用于进一步加速。
在 position delete 的基础上演化出了 delete vector,出要出发点在于不管是 partition-level 还是 file-level 的 position delete 文件都有局限。因此演化成现在的 delete vector 方式,这样磁盘和内存中的数据结构统一,每条数据仅会被删除一次,文件数也大大减少。
也有一些分享提了类似[29] first-row/last-row 的 merge option 等需求。
Catalog
Catalog 主要负责表层面的元数据,包括最新的元数据,事物控制协调等。现在 Iceberg 提供了多种类型的 Catalog 供用户选择。
本次 Summit 中有用户介绍使用 Catalog 的具体情况[6],也有介绍 RestCatalog 的相关事情[7][8][9]。
其中 Bloomberg 对不同的 catalog 有一些总结如下
- Hive
- Easiest to utilize, as we were already using the ApacheHive Metastore
- Scale and performance challenges
- AWS Glue
- managed service
- vendor lock-in
- access control limited through AWS primitives
- JDBC
- Easy and familiar to manage and connect to a database
- access control limited through AWS or DB primitives
- Rest
- Gave use the most flexibility to support the Iceberg Spec and additional custom features
- Flexible integration with different query engines
- Backed by a PostgreSQL database
- Provided the most flexibility on access control and multi-tenancy
[7][8]分享了 RestCatalog 的由来。RestCatalog 从最初解决 HiveCatalog 的问题出发(锁粒度,以及事物控制等),分析了一个 Catalog 需要满足的条件:可靠性,低延迟提交;事物/冲突管理;客户端的兼容性;数据的权限等。Iceberg 的 RestCatalog 将部分客户端的职责移到 server 端,这样客户端更轻量级;更好的事物控制(DML/DDL 的协调,合并和实时写入的协调),多表事物控制;客户端更好实现(更轻量级,更方便多语言实现)。以及 Apache Polaris 的一些实际使用情况。
[9] 分享了 Pinterest 使用 Gravtino 解决 Iceberg 过程中的一些实际问题,包括:partition list 很慢;性能分析;已经引擎相关的性能问题等。
Compute&Management
数据存储后会被查询使用,为了查询效率高也需要对数据进行管理优化。
[10] 主要分享了不同参数下 Iceberg 表的性能情况。主要在 file format 层面的调优,包括 write.target-file-size-bytes 和 write.parquet.row-group-size-bytes 的调优实践。一些具体的测试数据如下:
| metric | 2mb row-group size(unsorted) | 128mb row group size(unsorted) | 2m row group size(sorted) | 128mb row group size(sorted) |
|---|---|---|---|---|
| num_columns | 21 | 21 | 21 | 21 |
| num_rows | 391844 | 391844 | 1794155 | 656682 |
| num_row_groups | 33 | 1 | 150 | 1 |
| serialized_size | 94736 | 4824 | 424318 | 4799 |
并测试了不同引擎下的查询效率
- unsorted 情况下 2MB vs 128MB row group size 性能可以提升 15%
- sorted 的情况下 2MB vs 128MB row group size 性能可以提升 177%
[11] 分享了 Impala 优化 Iceberg MOR 的流程,主要思路是避免无限重复读取 delete 文件,单独一个算子读取 delete 文件,然后使用 broadcast join 来进行数据的删除。
[12] 分享了如果给 Iceberg 查询做 I/O 优化进行加速,主要思路是尽可能的进行 filter pushdown — filter pushdown is the gold standard of I/O optimizations
由于不是所有的 filter 都能够 pushdown,可以可能需要 rewrite SQL。现在 Iceberg 中 filter pushdown 会有如下约束
- Filters are only useful if they eliminate entire partitions or data files
- Limited set of statistics to evaluate with
- Lower and upper bounds
- Null, NAN, Value Counts
- Partition Values
- Not as useful for non-numberic cols
- Complex filters contain compute functions
- Iceberg transforms are only a subset
然后给出了一些 rewrite 的具体例子
| Before | After(completely pushable) |
|---|---|
| coalese(date, TODAY) <= TODAY | date is null or date <= TODAY |
| zip_code in (12345, 54321, 31524) | zip_code = 12345 or zip_code = 54321 or zip_code = 31524 |
| size / 2.0 > PARAM | size > PARAM * 2.0 |
| username LIKE ‘bill%’ | STARTSWITH(username, ‘bill’); |
| tag ILIKE ‘A’ | tag = ‘A’ or tag = ‘a’ |
对于无法全部下推的,可以考虑部分下推,如下所示
| original | runtime filter | file-level filter |
|---|---|---|
| url like ‘http://%.com% | startswith(url, ‘http://‘) and contains(url, ‘.com’) | startswith(url, ‘http://‘) |
| lower(name) = ‘adam’ (name ilike ‘adam’) | lower(name) = ‘adam’) | name = ‘ADAM’ and name =’adam’ |
| qyt INT > 100 | qty INT > 100 | qty is NOT null |
在最后对 Iceberg Metadata 提出一些需求,希望未来有更多可用于 file pruning 的 metadata 信息。
[13] 分享了 partition stats 的背景,当前情况等。主要是为了更好优化查询(CBO 过程)。
现在 Iceberg 有 FileLevel/Manifest Level/Snapshot Level 的指标,希望有 partition level 的指标。由于实际场景中大部分是分区表,因此 partition level 指标在现实世界中有很多使用场景。
- 避免读取所有的 manifest(有些表的 manifest 非常多)
- 在 plan 的时候可以 autoscaling(根据 partition level 指标动态调整并发)
- 动态调整 query plan(join reordering,IO operator)
- 仅在最新 snapshot 中 partition 会影响查询时进行合并
- 根据 partition 指标刷新数据写入链路(Two sigma 无法 expire snapshot 的例子)
[14] 分享了 Iceberg 的跨集群复制以及灾难恢复,主要思路是基于 snapshot 的增量复制。
[15] 腾讯(TEG) 分享了处理超宽表的一些线上生产经验,主要在 ML/DL 等场景下,会有上千列的情况。主要问题有:
- 表太宽,单表上 P
- 单表上千万的文件数量,上千数量的 manifest 文件
- plan 性能瓶颈
- batch 写入消耗内存多,容易导致 OOM
- 列管理困难
- 不是所有列的价值都一样
- 列的频繁增删
整体的思路包括:减少不必要的元数据(比如指标);通过 column stats 知道列的使用频率,然后进行调整;将 datafile 合并到 manifest file 中,减少文件数量;另外在合并的时候通过直接操作 parquet 来加速等一系列优化方案。更详细的可以查看对应视频。
[16][17][18] 有讲表管理、优化相关的事情(和 Amoro 定位类似,Linkdin 开源了他们的 OpenHouse),这里面有比较多实际生产经验可以借鉴,包括合并策略、资源优化、扩展性、观测性(用户侧,服务侧)、告警等
[22] 分享了腾讯云基于 Amoro 做的流批一体的湖仓系统,包括 MixedIceberg 承接实时数据,以及支持 partial update 等需求。
File format
为了满足不同的场景(尤其是 ML&AI),有不同的 file format 出来(lance, vertox 等),如何在 Iceberg 中结合新型 file format 的能力是一个社区正在做的事情。
[19]分享了 fileformat 出现的一些原因,以及 Iceberg 正在做的事情 — 抽象 FileReader/Writer 的接口等。
- ML workload 的特点
- wide columns
- both scan & search
- grow horizontally(wide schema)
- 新硬件的特点
- not just(or even primarily) run on CPUS
- Accelerators like GPU & FPGA are embarrassingly parallel
- Common bottlenecks: CPU, Copying to device memory
- IDEA: Load compressed data, decompress on-device
新的 file-format 要求和特点如下所示
- 要求
- Decompression via GPU SIMT
- Decompression via CPU SIMD
- Random access on compressed data
- 特点
- workload diversity
- flexibility & interop
- accelerated computing
[15] 中腾讯的分享是在 parquet 中做的一些工作。
Streaming
随着大家对实时入湖的需求,以及 Iceberg 在实时入湖上的现状,大家在寻找时效性,湖仓治理的一个平衡点。
不同公司也在尝试实时入湖的事情,如何做到时效性、管理成本等的平衡是一个难点。
[20] 分享了 Snowflake 在 Iceberg 上做增量计算的一些事情,这个分享包括了增量计算的定义,以及在 snowflake 中实现的一些思路,思路大概是通过 row_id 来记录数据的演进(row_id 也可以当成 watermark),然后通过代数变换讲 join 等算子变换为增量计算的算子减少计算量。比较麻烦的是多表事物的处理 — 需要有一个全局的时间。
[21] 分享了实时入湖效率,以及后续湖仓内数据治理的一些实测数据,希望达到一个全局的最优,主要思路是在不影响 compaction 的情况下增大入湖效率(增大写入并发),然后通过类似 RestCatalog 的角色来协调 commit。另外会对一些错误配置等提前预判并通知。
[26] 分享了如何实时入湖相关的事情,并给出了从 Snowflake 迁移到 Iceberg 的一些情况,并且基于实际情况提出了 Flink Dynamic Schama 的需求,在最新的 Sink 中有相关的工作正在进行中。
Ecosystem(&usecase &migration)
[6] 有分享迁移到 Iceberg 前后的收益
| Before Iceberg | After Iceberg |
|---|---|
| Full daily restatements of 7TB+ | Incremental daily revision between 5~10 GB(<1% of total table) |
| High ingestion overhead | Streamlined ingestion and processing |
| Slow processing and costly storage | Efficiency gains in storage and compute |
| Hard to diagnose and debug data quality | Easier to diagnose and debug data quality |
[17][25][27]分享了 Hive 迁移到 Iceberg 的一些事情,描述了 Hive 的一些限制:partition 支持不好;ACID 支持不好,性能,扩展性,多引擎支持等等,以及从 Hive 迁移到 Iceberg 的详细流程和 checklist,包括前期分析,迁移计划,具体执行,以及最后验证等,对于 Hive 迁移 Iceberg 的可以参考下。从 Hive 迁移到 Iceberg 后,整体减少了 70% 的资源,查询峰值时间降低了 95%,对于 streaming 入湖也更简单了。
[9] 使用 Iceberg 做流批一体存储,链路大致如下 [upstream] -> kafka -> flink -> Iceberg -> [Flink/Spark],使用了两张表来承接实时数据:其中一张表保留全量数据,一张表保留增量数据,增量数据周期性写入全量表(Amoro 中的 mixed-iceberg 思路类似)。
[23] 分享了使用 Trino 做可扩展的湖仓,主要解决如下问题:扩展性;管理难度;查询性能慢;vendor lock-in 等。
在扩展性方面遇到:metadata 增长;不同的 workload;查询性能的稳定;数据倾斜的处理以及限速等。
基于生产经验总结了一些最佳实践:
- 读方面:使用 NDV Status,filter pushdown, metadata/data cache,materialized view(trino),合适的线程池大小等
- 写方面(主要是 trino 相关):限制写入并发;数据合理分区,专用 plan/delete 的线程池等
[23] 分享了使用 Iceberg 做统一存储后,避免在各系统之间进行数据的传输,计算等,减少了整体的计算和存储量。
[24] 分享了构建基于 Iceberg(+StarRocks/BigQuery) 的大规模分析系统,并且在生产中实现了 blue/green 的常规流程。 使用 Iceberg 前后的对比如下所示(之前是 PG 和 BigQuery)
| Before | After |
|---|---|
| 大查询经常超时 | 查询耗时大规模减少 P95 2.976s Avg 1.65s |
| increasing SSD costs to store ever increasing volumes of data | 数据可以 offload 到 object storage |
| 存算一体(耦合) | 存算分离(可以单独扩展) |
| Hourly and daily data loads frequently resulted in SLO misses | 存储只需要在一个地方就行 |
| 无法很容易的换计算引擎 | 可以使用多引擎查询 |
| 数据太大需要从 PG 切到 BigQuery,无法在 on-premise 环境 | 可以在 on-premise 环境使用 |
[28] 则分享了 PG 支持 Iceberg 外表的一些情况,这样可以结合 PG 和 Iceberg 的能力。
[30] 分享了 Redpanda 的 iceberg table,听起来和Automq 的 iceberg table 以及 fluss 有相似之处,可以将 MQ 的数据直接 compaction 到 datalake 中,这块或许一个完整的是,有轻量级 MQ + service 能力负责 offload 和 compaction,以及现在的 datalake。
[31] 则分享了生产中实际情况,比如使用 storage partitioned join 来避免大量 shuffle 的场景。
另外类似 Trino/StarRocks/BigQuery 等引擎均在大会上分享介绍如何结合 Iceberg 的,在语言方面,除了 Java 之外,现在 Python/Rust/C++ 等语言也在积极推动中。
Ref
[0] https://www.icebergsummit2025.com/agenda/
[1] V3 and Beyond Iceberg’s ongoing evolution
[2] Decoupling Metadata: Leveraging Queryable Iceberg Tables for Scalable, Cross-Engine Innovation
[3] Understanding Deletion Vectors in Apache Iceberg
[4] Iceberg Geo Type: Transforming Geospatial Data Management at Scale
[5] Decoupling Metadata: Leveraging Queryable Iceberg Tables for Scalable, Cross-Engine Innovation
[6] Building Bloomberg’s First Incremental Alternative Data Product Using Apache Iceberg
[7] Pioneering the Next Frontier: The REST Revolution in Apache Iceberg Metadata
[8] Scalable Lakehouse Architecture with Iceberg & Polaris: A Battle-tested Playbook
[9] Scaling Iceberg Adoption at Pinterest with Gravtino
[10] Deep Dive into Iceberg Optimizations and Best Practices for a Scalable and Performant Lakehouse
[11] Extending the One Trillion Row Challenge to Iceberg V2 Tables
[12] Iceberg I/O Optimizations in Compute Engines
[13] Supercharging Apache Iceberg Strategies for Harnessing Partition Stats
[14] Iceberg Resilience: Building a DR Strategy for the Data Lake
[15] Efficiently Managing Table With Thousands of Columns Using Iceberg In Tencent
[16] Learning from running large-scale Apache Iceberg Table Management Service
[17] Airbnb Icehouse: The Journey to Iceberg
[18] Optimizing Iceberg Table Layouts at Scale: A Multi-Objective Approach
[19] Turbocharge Queries on Iceberg with Next-Gen File Formats
[20] CDC Implementations on Apache Iceberg and where are we headed
[21] Unleashing the power of Iceberg ingestion 100GB/s and beyond
[22] Building a Batch-Stream-Unified Lakehouse on Apache Iceberg in Tencent Cloud
[23] Eliminating redundancies in ETL with Iceberg tables on Snowflake
[24] From zero to one: Building a petabyte-scale data analytics platform with Apache Iceberg
[25] Hive Tables to Apache Iceberg: A Step by step Migration Blueprint
[26] Iceberg with Flink at DoorDash
[27] Implement Iceberg for Improved Data Management at Autodesk
[28] Postgres meets Iceberg
[29] Supercharging wise data lake with apache iceberg
[30] The ‘Streamhouse’: Extending Redpanda into a fully managed, Iceberg-backed realtime data lakehouse
[31] Adopting Apache Iceberg at Slack: Challenges, Lessons, and Best Practices